免费硕士学士论文 基于多模态大模型的仿人机械手作业控制方法设计实现
1. 引言
| 挑战维度 | 具体表现 | 示例领域/现象 |
|---|---|---|
| 研发周期漫长 | 新药研发耗时10-15年 | 新药研发[33,35] |
| 投入成本巨大 | 新药研发投入数十亿美元 | 新药研发[33,35] |
| 成功率较低 | 临床试验成功率不足10% | 新药研发[33,35] |
| 基础原理应用难 | 许多基础原理难以有效应用于解决实际问题 | 复杂系统机理刻画[26] |
| 实验效率低下 | 实验手段和数据处理效率低下,依赖经验和试错 | 科研工作普遍存在[26] |
| 数据处理挑战 | 面对爆炸式增长的数据难以有效处理 | 各科学领域大数据问题[42] |
| 特定任务耗时 | 如蛋白质结构解析,传统方法耗时数年 | 蛋白质结构解析[28] |
传统的科学研究范式虽然推动了人类知识体系的巨大进步,但在面对日益复杂的科学问题和爆炸式增长的数据时,其固有的局限性逐渐显现[42]。具体而言,传统方法往往面临研发周期漫长、投入成本巨大、研究成功率较低等挑战[25,35,40],例如新药研发常需耗时10至15年,投入数十亿美元,而临床试验成功率却不足10%[33,35]。此外,许多基础原理难以有效应用于解决实际问题,实验手段和数据处理效率低下,科研工作常依赖于经验和反复试错,效率亟待提升[26]。对于蛋白质结构解析等任务,传统方法如核磁共振和X射线晶体学,不仅耗时高昂,且可能需要数年时间才能解析一种蛋白质的三维结构[28]。这些困境促使科学界寻求新的研究范式。
在此背景下,人工智能(AI)技术的蓬勃发展,特别是以ChatGPT为代表的大模型技术的突破性进展,为科学研究带来了前所未有的机遇,推动了人工智能驱动的科学研究(AI for Science, AI4S)作为一种新的、甚至是第五科学研究范式的兴起[10,15,42]。AI4S被定义为人工智能技术与科学研究深度融合的产物,旨在通过数据、算力、算法的深度耦合,嵌入科学研究的全过程,引发科研流程、思考逻辑和组织模式的深刻变革[13,21]。许多科学家认为,以虚实交互、平行驱动的AI技术为核心,AI4S将成为科学发现的第五范式[10,15],超越了早期的实验范式、理论范式、计算模拟范式以及大数据驱动的第四范式[7,13]。
大型语言模型(LLMs)作为大模型的代表,凭借其在处理海量复杂数据、理解和生成文本方面的显著优势,在AI4S中扮演着日益核心的角色[3,32]。通过大规模数据训练,LLMs能够以前所未有的能力处理、分析并从多模态科学数据中挖掘深层关联,加速研究进程,并辅助生成新的科学假设和见解[2,3,20,41]。它们的应用潜力体现在科研周期的各个阶段,包括假设发现、实验规划与实施、以及科学写作与同行评审等[2]。例如,在蛋白质结构预测领域,AI大模型如AlphaFold[16,34]和HelixFold-Single[28]已展示出预测高置信度结构的强大能力,速度远超传统方法[28],极大推动了生物化学等领域的发展。在生物医学领域,专门为生物医学设计的模型已在临床沟通、基因分析和决策支持等方面显示出潜力[22]。
全球主要国家已认识到AI4S的重要性,并积极进行战略部署。早期计算机辅助研究可追溯至20世纪70年代,但AI4S的全面兴起是近期之事[2]。当前,“人工智能驱动的科学研究”已成为全球人工智能新前沿[21]。美国能源部(DOE)和国家科学基金会(NSF)是AI4S的主要推动力量,DOE已发布综合性技术报告,为AI4S确立发展方向[7]。我国也高度重视AI4S的发展,将其视为抢抓未来科技创新方向、形成国际科技竞争优势的关键所在[13]。为贯彻落实国家《新一代人工智能发展规划》,科技部会同国家自然科学基金委员会近期启动了“人工智能驱动的科学研究”专项部署工作,旨在紧密结合基础学科关键问题和重点领域科研需求,布局前沿科技研发体系[15,21,44]。国内多地如北京、上海、四川、广东、浙江等也纷纷展开相关部署工作[44]。
本文旨在系统综述大模型驱动的科学发现在当前的研究进展、核心技术、典型应用及其面临的挑战与未来发展方向。本综述聚焦于大模型在科学发现中的应用,特别是其在生物医学(包括药物研发、基因组学、医疗诊断等)和材料科学等领域的最新进展[22,25,29,37,38,40]。文章结构如下:第二部分将详细阐述大模型的概念、原理及其在科学研究中应用的普适性基础;第三部分将重点介绍大模型在生物医学领域的具体应用和突破;第四部分将探讨大模型在材料科学领域的应用进展;第五部分将分析大模型驱动科学发现面临的关键挑战,如数据、计算、模型泛化能力、可解释性及伦理问题等;最后,第六部分将对全文进行总结,并展望该领域的未来研究方向。本综述期望为相关领域的研究人员提供有价值的参考,共同推动AI4S范式的深入发展。
2. 科研范式变革与大模型的基础
科学研究的范式是科研人员认识世界、探索未知所遵循的基本程序、逻辑、世界观及方法论体系 [13]。回顾历史,科学研究范式经历了显著的演变,从依赖感官观察和归纳经验的经验范式,到基于抽象与数学构建理论的理论范式,再到借助计算工具进行模拟与仿真的计算范式,随着数据量的爆炸式增长,又进入了以大数据分析为核心的数据驱动范式 [15,21,42]。图灵奖得主 James Nicholas Gray 将上述四种范式界定为科学研究的主要阶段 [15]。
目前,伴随新一代人工智能技术的迅猛发展与深入应用,科学研究范式正迈向一个全新阶段,被广泛视为“人工智能驱动的科学研究”或“AI for Science”范式,即科学研究的“第五范式” [15,21,42,44]。这一新范式并非完全脱离或取代前述四种范式,而是在它们的基础上实现推进、提升与多元耦合 [13],从而形成以虚实交互、平行驱动为核心、深度融合数据、计算、理论与实验的新模式 [15]。人工智能驱动的科研模式正重塑传统“作坊式”研究流程,使之向更高效、更系统化的“平台科研”模式转变 [21,26]。同时,人工智能的应用正不断扩展到物理、化学、生物、医学等多个学科领域,成为推动基础科学实现重大发现和突破的关键力量 [21,44]。
在人工智能驱动的科研新范式中,大型模型,特别是大语言模型(LLMs),扮演着至关重要的角色。这些模型拥有庞大的参数规模和复杂的网络结构 [38],通过在海量数据上的训练习得丰富而细致的特征表示能力,从而在处理复杂数据、捕捉细微特征及实现高效预测与推理方面展现出超越传统模型的显著优势 [38]。大型模型能够处理高维问题,为因“维数灾难”而长期难以解决的科学难题提供了全新的工具和范式 [10,21]。它们在生物医学领域(如蛋白质结构预测 [28])以及材料科学领域(如新材料设计与发现 [9])中,都展现出强大的应用潜力。
本章节将首先深入阐述作为科学研究第五范式的 AI for Science 的内涵及特征,并探讨其与前四种范式的联系与区别;随后,详细介绍大型模型的概念、核心原理及其相对于传统模型的优势,同时分类比较不同大语言模型架构在生物医学等领域的应用案例;最后,将分析人工智能驱动科研新范式从科研自动化、科研模型化到科研智能化的演化方向与各阶段特点。
2.1 AI for Science作为第五范式
科学研究的范式随着人类认识世界能力的提升和技术进步不断演进。回顾历史,科研范式经历了从以观察和归纳为主导的“经验科学”向基于抽象和数学模型构建的“理论科学”发展的转变[13]。伽利略提出的物理学和动力学是经验科学的典型代表,其侧重于通过描述和记录自然现象,并基于经验进行归纳[13];而牛顿力学和相对论则标志着理论科学的成熟,在自然现象的基础上进行抽象与简化,并构建数学模型加以总结[13]。
随着计算能力的跃升,科研进入了“计算科学”范式,借助电子计算机对科学实验进行模拟仿真,例如核试验和天气预报的模拟[13]。随后,由于数据量的爆炸式增长和计算设施的不断升级,“数据密集型科学”应运而生,这种由传统假设驱动转向基于科学数据驱动的研究范式[13]。1998年,图灵奖得主James Nicholas Gray将这种大数据主导的科学知识生产方式定义为科学的“第四范式”[7]。
当前,科研范式正迈向被广泛认为是“第五范式”的新阶段,即“人工智能+科学”[13,42]。不同学者对这一新范式持相似定义,其核心在于以人工智能技术和数据驱动为基础[42]。这种范式并非独立于前四种范式之外,而是与其存在明显的继承、发展、相互渗透和融合关系[42]。人工智能驱动的科研范式被认为是“四大范式+AI”的实现路径[42],其依托海量数据和强大算力进行通用人工智能大模型的训练与优化,旨在发挥人工智能在精度、效率、可迁移性和涌现性等方面的优势,从而解决系统性复杂问题,并显著影响科研的组织模式[13,42]。
用于科学的人工智能范式的关键在于其对传统科研能力的赋能作用[42]。人工智能能够有效提升实验、理论、计算和数据等各个方面的能力[42]。在实验层面,人工智能推动实验设备向更高效、更精准的方向发展[26];在理论和计算层面,机器学习具备处理高维问题的能力,使得人类可以更加真实细致地刻画复杂系统的机理[26]。例如,科学研究中常遇到的“维数灾难”——随着自由度(维数)增加,计算量呈指数增长,导致许多实际问题只能采用粗糙方法加以解决[10]——可以通过机器学习在高维空间内的强大处理能力得到缓解,从而以更高效、实用的方式将基本原理应用于实际问题的解决[26]。在数据层面,数据驱动方法贯穿研发全过程,包括假设的建立、数据的获取、处理、分析以及知识的提取[9]。人工智能能够帮助全面而准确地提取人类多年积累的知识[26]。
总体来说,人工智能赋能的科学研究正展现出在推动科研创新、提升研究效率以及解决复杂科学问题方面的巨大潜力[44]。这一范式推动科研从以往主要依赖“人脑”的模式向人机协同转变[42],在许多领域中,人工智能展现出超越传统数学或物理方法的强大能力[21]。例如,人工智能与基因计算的融合正在加速,有望在生物育种、医疗健康和生物医药等领域开辟新前景[44];而材料信息学则利用数据中心方法推动新材料的设计与发现[9]。然而,人工智能驱动的科学研究仍需在体系化布局、重大系统设计、跨学科交叉融合以及创新生态构建等方面进一步提升[21]。
2.2 大模型的概念与核心技术
大模型,作为具有庞大参数规模和复杂结构的深度学习模型,通过在海量数据上进行训练,展现出学习到更加丰富和细致的特征表示的能力[38]。这使得大模型能够实现更加精准和高效的预测和推理,在处理复杂任务和场景时表现出更强的表达能力和泛化能力[38]。其核心原理在于通过庞大的参数规模和复杂的网络结构捕捉数据中的更多细节和特征信息[38],并采用不同的训练策略和优化方法来提高性能和效率[38]。例如,蛋白质结构预测模型 AlphaFold 即利用深度学习构建多层神经网络,从数据中学习复杂模式,实现精准预测[8]。大型语言模型(LLMs)作为一类特殊的机器学习模型,尤其擅长处理文本数据,其核心在于处理更大的数据集、采用复杂的架构设计,并利用自监督学习技术减少对昂贵数据标记的需求[3]。AI 在处理高维问题方面提供了有效的解决方案,例如图像识别或复杂系统机理刻画,通过神经网络逼近高维函数,这为科学研究提供了新的工具和范式[10,21]。预训练模型被视为未来趋势,已成为 AI 应用的基础设施,例如自然科学领域的 DPA-1 模型,通过预训练和复用降低了研发成本[26]。
LLMs 的设计通常基于 Transformer 架构,该架构特别擅长捕捉长序列的上下文关系[8]。基于 Transformer 架构的 LLMs 可主要分为三种类型[22,32]:
- 仅编码器模型(Encoder-only):此类模型专注于输入数据的表示和理解,通过双向编码获取上下文信息[22,32]。在生物医学领域,代表性模型如 BERT 及其变体 scBERT、BioBERT,适用于文本分类、命名实体识别和基因嵌入等任务[22]。
- 仅解码器模型(Decoder-only):此类模型主要用于生成输出数据,擅长文本生成和对话系统[22,32]。GPT 系列及其衍生的 BioGPT、CancerGPT 是典型代表,在生物医学中应用于生成医学报告和药物发现等任务[22]。
- 编码器-解码器模型(Encoder-Decoder):此类模型结合了编码器和解码器的功能,适用于序列到序列的任务[22,32]。T5、BART 以及其生物医学应用 BioBART、GeneCompass 属于此列,可用于机器翻译、文本摘要和基因调控机制解码等[22]。大型语言模型(LLMs)及其生成式技术在文本类任务以及综合性、高数据密度、多流程任务中展现出显著的助力作用[12],并且在大模型的框架下,大模型与小模型协作的模式预计是近几年的主流市场应用方式[12]。生成对抗网络(GANs)是另一类强大的机器学习算法,属于生成式模型,能够用于在虚拟环境中创造新化合物结构并预测其表现[9,29]。
为使通用 LLMs 适应生物医学等特定领域,微调技术至关重要,旨在增强模型对领域专有术语和复杂概念的理解[22]。常见的微调技术包括全参数微调(如 GatorTron)、指令微调、参数高效微调(PEFT,如 LoRA、QLoRA)以及混合微调策略[22]。这些技术能够在提高模型在特定领域性能的同时,在部分情况下减少计算资源消耗[22]。
尽管大模型及其核心技术取得了显著进展,但现有研究在公开信息上存在一定局限。部分文献对大模型概念的阐述停留在利用大规模数据和复杂算法的层面,未能深入探讨具体的关键技术,例如参数规模、详细的网络结构、训练策略或优化方法[28,31]。此外,并非所有关于大模型应用的介绍都详细提及了其采用的具体架构类型(编码器、解码器、编码器-解码器)或所使用的微调技术[28,31]。这种信息上的不充分性可能会影响对模型技术先进性的全面理解。目前的许多 AI 工具倾向于面向特定领域的特定问题,存在可复制性不足的挑战,甚至在同一学科的不同子领域工具间也存在显著差异,这凸显了构建跨学科通用 AI 工具的复杂性[18]。未来研究需要进一步深入和系统地揭示大模型在科学发现中应用的技术细节,包括其精确的架构选择、高效的训练与优化方案,以及针对不同科学领域进行微调的具体策略与效果比较,从而推动该领域的理论发展与应用实践。
2.3 AI驱动科研新范式的演化阶段
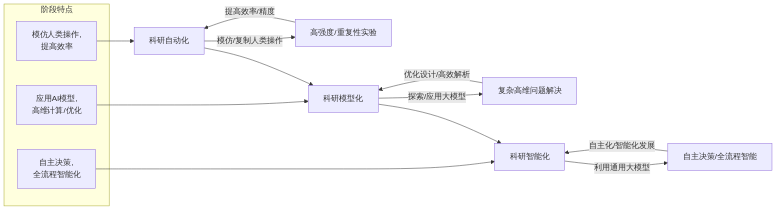
人工智能(AI)正在深刻影响科学研究,推动科研范式由传统模式向AI驱动的新范式演进。这一演化过程呈现出从“科研自动化”到“科研模型化”,再到“科研智能化”的清晰方向[13]。每个阶段都标志着AI在科研中应用的深度、广度以及自主性的显著提升,共同构建了面向未来的科学发现体系。
科研自动化是AI驱动科研新范式的初级阶段,其核心在于通过模仿和复制人类专家的实验操作过程,替代科研人员执行高强度、高重复性、高频率且需要高精度的科学实验与试错任务[13]。这种自动化能够显著提高实验效率,减少人为误差,并解放科研人员的时间,使其能更专注于创造性工作。在不同实验环境下,实验室自动化可以采取多种形式,包括单模块自动化、工作站形式自动化、流水线形式自动化以及更高级的机器人形式自动化[13]。具体应用涵盖多个科学领域,例如AI在天文学中用于数据挖掘和模式识别以识别新星系,在生物学中应用于蛋白质折叠预测,以及在材料科学中预测新的超导材料[5]。传统材料科学研究往往依赖耗时费力的实验方法,而AI的引入,即使是在自动化阶段,也能通过在虚拟环境中快速筛选潜力材料,再进行实验验证的方式,大幅加速新材料的发现过程[29]。科研自动化的一个最终目标是实现人类监督下的自动运行实验室[9]。
科研模型化是AI驱动科研范式演进的中间阶段,其核心在于探索和应用AI大模型来优化实验设计,实现传统计算方法难以企及的高维计算和高效解析能力[13]。通过构建和依托特定领域的AI模型,科研人员能够解决复杂的高维度科学问题,从而在生物学、物理学等领域推动重要突破[13]。例如,AI系统能够分析海量医学文献和临床数据,提出新的疾病机理假设;AI结合量子计算可用于粒子物理研究;AI驱动的分子设计平台能够预测化学反应路径[5]。最先进的AI大语言模型(LLM)能够从人类历史上积累的全部科学文献中整合知识,提供前所未有的信息整合能力,并提高实验设计和数据分析的效率[36]。中国科学院工程热物理研究所基于AI模型提出的等效特征图谱法(ECSA),通过智能仪器和程序实现了对气体图谱的精准识别,是科研模型化的一个具体应用案例[13]。在智能化科学设施的架构中,跨学科、跨模态的科学大模型以及“AI科研助手”构成了重要的科学模型层[18]。
科研智能化代表了AI驱动科研范式的未来方向和高级阶段,强调利用通用大模型和持续的模型优化,赋予AI在复杂和高任务量科研过程中自主决策的能力[13]。这一阶段旨在实现科研流程的自主化和智能化发展。智能大模型与科研设备的深度融合是科研智能化的关键特征,能够促进复杂研究过程中的智能决策能力提升[13]。应用实例包括AI辅助优化基因编辑实验参数、通过模拟分子对接筛选潜在药物,以及机器人实验室与AI结合进行材料性能测试[5]。在智能化科学设施的愿景中,AI操作机器人和智能实验环境位于实验应用层,与科学模型层和基础支撑层共同形成人在环路的科学智能大设施体系[18]。AI科学家概念在这一阶段得以实现,它们能够自动化文献回顾、实验数据分析和假设生成,展现出超越人类的能力,并有可能通过数字孪生技术实现从全细胞到全人类的虚拟模拟和系统性理解[36]。
总而言之,AI驱动的科研新范式正从执行重复任务的自动化,发展到利用大模型进行高效计算和复杂问题分析的模型化,并最终迈向具备自主决策能力的智能化阶段[13]。这一演进不仅拓展了AI在科研中的应用深度和范围,也加速了科研与产业之间的连接,有望建立以产业需求推动科研的有效体系,类似于“安卓模式”在平台科研中的应用潜力[26]。
3. 大模型在生物医学领域的应用
随着高通量技术的发展,生物医学领域产生了海量且日益复杂的多模态数据,这使得传统的分析方法面临巨大挑战 [38,39]。在此背景下,人工智能,特别是大型模型(Large Models, LMs)和大型语言模型(Large Language Models, LLMs),凭借其强大的数据处理、模式识别和泛化能力,在生物医学领域展示出巨大的应用潜力 [22,38,39]。这些先进的AI工具正革新着多个生物医学子领域,显著提升了研究效率和准确性,并为全新的科学发现提供可能 [7,12,32]。
| 应用领域 | 核心活动/AI赋能 | 典型示例/模型 |
|---|---|---|
| 蛋白质结构与功能预测 | 预测三维结构、动态构象、蛋白质相互作用;预测蛋白质功能 | AlphaFold系列, HelixFold-Single, AlphaFolding, DynamicBind, DPFunc, ESMFold |
| 药物发现与开发 | 靶点识别、虚拟筛选、药物设计、ADMET预测、合成规划、临床试验优化 | AtomNet, PocketFlow, AlphaFold 3, ChemCrow, DSP-1181, DrugFormer, LEDAP, 文思智能平台 |
| 基因组学与组学研究 | 序列分析/注释/生成、疾病相关基因/变异挖掘、疾病风险预测、单细胞数据分析 | Evo, LucaProt, scGPT, scBERT, BioBERT, GeneCompass, GeneGPT, DeepCas13, Linear Design |
| 临床诊断与个性化医疗 | 诊断辅助、医学影像分析、个性化治疗方案制定、疾病风险预测、生物标志物发现 | GPT-4 (诊断), CHIEF (癌症影像), Deep Learning (影像分析), PathChat, DrugFormer (耐药性) |
大型模型在生物医学中的应用范围广泛,涵盖了从基础研究到临床实践的各个环节 [23,31]。例如,在蛋白质结构与功能预测领域,大型模型被广泛应用,从而彻底改变了人们对生命基本构成单元的认识 [8,15,17,19,30];在药物发现与开发领域,AI技术贯穿靶点识别、分子设计、ADMET预测乃至临床试验优化的全流程,显著缩短了研发周期并提高了成功率 [3,19,20,21,25,35,36,42];在基因组学与组学研究领域,大型模型能够高效解析复杂的基因组、转录组、蛋白质组等多模态数据,挖掘与疾病相关的基因和变异位点,并辅助发现生物标志物及预测疾病风险 [1,7,10,23,39];此外,在临床诊断与个性化医疗方面,AI模型同样发挥着越来越重要的作用,通过整合医学影像、电子病历和基因组信息,为医生提供精准诊断支持,并为患者制定个性化治疗方案 [7,12,22,31,35,39,43]。
本章节将依据上述关键子领域进行分类阐述,深入探讨大型模型如何赋能生物医学研究,并分析其所带来的机遇、挑战及未来的发展方向。
3.1 蛋白质结构与功能预测
蛋白质的三维结构与其功能密切相关,对其精确解析是理解生命过程的关键[28]。长期以来,传统的实验室观测方法如X射线晶体学和核磁共振波谱法虽然提供了宝贵的结构信息,但其过程昂贵且耗时,导致已解析结构的蛋白质数量远少于已知的蛋白质序列[28]。人工智能,特别是大模型的兴起,为蛋白质结构与功能预测领域带来了革命性的变革[15]。
AlphaFold系列模型由DeepMind开发,是这一领域的标志性突破[15]。AlphaFold利用深度学习技术,能够从蛋白质的氨基酸序列预测其三维结构[30,42]。其核心创新在于采用深度学习模型,通过分析大量已知结构数据进行训练,并结合多序列比对(MSA)技术推断保守结构特征,同时引入几何约束确保预测结构的物理合理性[30]。AlphaFold 2在蛋白质结构预测技术关键测试(CASP)比赛中取得了中位数高达92.4分(满分100分)的高分预测结果,证明了端到端深度学习架构在蛋白质结构预测上的可行性与高精度,甚至达到了原子大小尺度的差异[8,34]。AlphaFold 2结合了基于蛋白质结构进化、物理和几何约束的新型神经网络架构与训练程序,显著提高了预测准确度,且可在几分钟内完成蛋白质结构预测[19]。在CASP15中,至少有40支队伍的预测精度超越了AlphaFold 2,进一步凸显了其对该领域的巨大推动作用[34]。
AlphaFold 3在此基础上进一步拓展了预测范围和能力。它不仅能够预测蛋白质的三维结构,还能预测几乎所有生命分子的结构,包括DNA、RNA、配体等,并能预测蛋白质与其他分子类型的相互作用[4,8,19,32]。AlphaFold 3采用了升级版的Evoformer模块和全新的扩散网络(Diffusion Network)架构,从“原子云”开始通过迭代细化预测精确结构,简化了模块设计以提高效率和准确性[4]。它在预测类药物相互作用(如蛋白质-配体界面)方面实现了前所未有的准确度,在PoseBusters基准集上报告的口袋与配体RMSD小于2 Å,优于传统对接工具,且无需结构信息输入,成为首个超越传统物理预测工具的AI系统[4,32]。此外,AlphaFold 3提高了蛋白质复合物的准确性(尤其在抗体-蛋白相互作用预测上),并能准确预测共价修饰[4]。
AlphaFold系列的突破对生物医药领域产生了重大影响,加速了药物研发进程[16,19,30]。通过预测蛋白质结构,研究人员可以预测药物分子与蛋白质的结合位点和亲和力,从而优化药物设计[37]。基于结构预测已产生了诸多临床应用,如小蛋白设计、细胞因子(如白介素2)的AI设计以及工业酶的改造[16]。AlphaFold的成功证明了AI和计算技术在生物医药领域的巨大潜力[16]。
尽管AlphaFold系列取得了巨大成功,但也存在一些局限性。AlphaFold 2的预测精度与目标结构在PDB中是否有同源物密切相关,对“孤儿蛋白”(序列同源性低的蛋白质)的预测精度仍然有限[34]。对于多结构域蛋白质,其预测精度不如单个结构域,域间取向预测更具挑战性[34]。此外,AlphaFold系列主要预测的是蛋白质的静态三维结构,难以捕捉蛋白质在生理条件下的动态构象变化,而这种变化对于理解蛋白质功能和相互作用至关重要[17,19,34]。传统的AlphaFold 2等模型依赖于MSA检索,这可能成为速度瓶颈[28]。
为了解决AlphaFold 2对MSA的依赖并提升预测速度,百度飞桨螺旋桨联合百图生科研发了HelixFold-Single模型[28]。该模型是全球首个开源、提供在线服务且无需MSA输入的蛋白质结构预测大模型,打破了依赖MSA的速度瓶颈,将预测速度平均提高数百倍,实现了秒级别预测[28]。例如,预测一个长度为697的蛋白质(门蛋白7et2_H),AlphaFold 2需要1280秒,而HelixFold-Single仅需11秒,速度提升了115倍[28]。
为了让更多研究人员能够便捷地使用AlphaFold 2进行预测,开发了ColabFold工具[14]。ColabFold简化了AlphaFold 2的使用流程,降低了技术门槛。它在单体蛋白质结构预测上表现优秀,对人GPIT蛋白亚基的预测精度较高(pLDDT >80, TM >0.83),表明其能稳定预测单体结构并突破了以往算法对MSA质量和数量的依赖[14]。ColabFold还展现了预测蛋白质复合物结构的能力,对GPIT五聚体的预测结构与实验结果高度一致(TM得分0.985,亚基间界面ipTM 0.899),实现了更大、更复杂体系的从头预测,为推断蛋白质相互作用提供了基础[14]。
针对蛋白质动态结构的预测需求,新兴的动态蛋白质结构预测方法应运而生。复旦大学、上海科学智能研究院和南京大学的研究团队提出了AlphaFolding模型,这是一种创新性的4D扩散模型,结合分子动力学(MD)模拟数据来学习蛋白质的动态结构,能够同时预测多个时间步长的运动轨迹[17]。AlphaFolding在基准数据集上对包含最多256个氨基酸、跨度达32个时间步长的动态3D结构表现出高精度预测能力,有效捕捉稳定状态下的局部柔性及显著的构象变化[17]。此外,DynamicBind等模型也致力于解决蛋白质动态对接问题,能够将AlphaFold预测的初始结构调整至更接近结合状态的构象[17]。RoseTTAFold和DiG等模型也在蛋白质结构解析和构象采样方面做出了贡献[17]。结合扩散模型和蛋白质语言模型来理解蛋白质“交互组”的原子级细节,并增强AI加速的动力学模拟,是未来生物发现的重要方向[36]。
除了结构预测,蛋白质功能预测同样重要。中南大学提出的DPFunc模型利用深度学习进行蛋白质功能预测,取得了新突破[24]。DPFunc模型结合了预训练的蛋白质语言模型(如ESM-1b)和图神经网络来学习残基级特征[24]。模型引入注意力机制评估残基重要性,并交织蛋白质水平结构域特征与残基水平特征,能够检测蛋白质结构中与功能密切相关的关键残基或区域[24]。DPFunc在处理低序列同一性的不可见蛋白质、高IC值的信息性GO项以及更深节点的特定GO项时,表现出优于现有SOTA方法的明显优势[24]。然而,该模型在无序区域寻找活性位点仍面临挑战[24]。蛋白质语言模型在功能预测和设计方面也展现出潜力,例如ProGen是一种深度学习语言模型,通过在大量蛋白质序列上训练,并利用控制标签指定蛋白质特性,能够生成具有可预测功能的蛋白质序列[3]。Meta AI团队开发的ESMFold模型通过大型语言模型直接从一级序列推断全原子级蛋白质结构,内在化了与结构相关的进化模式,无需外部数据库或MSA[32]。EvolutionaryScale团队的ESM3蛋白质语言模型则致力于设计相当于模拟自然进化的新蛋白质[32]。
总而言之,人工智能大模型已显著推动了蛋白质结构与功能预测领域的发展。AlphaFold系列在静态结构预测上取得了革命性突破并加速了药物研发,但仍面临预测动态结构、孤儿蛋白及多结构域蛋白质的挑战[17,34]。HelixFold-Single和ColabFold等工具则在预测速度和易用性方面进行了优化[14,28]。新兴的AlphaFolding模型开始探索动态结构预测,而DPFunc等模型则专注于利用深度学习进行功能预测,并取得了显著进展[17,24]。未来研究将可能围绕提升动态预测能力、克服无序区域的预测难题、优化复杂体系预测以及更紧密地整合结构与功能预测模型等方面展开。
3.2 药物发现与开发
人工智能(AI),特别是大型语言模型(LLMs),正在深刻地重塑药物发现与开发的各个环节,贯穿从靶点识别到临床试验的全流程 [3,33,36,40]。AI制药通过数据驱动和模型驱动方法的结合,有望构建更加系统、高效、自动化的药物研发过程,为新型疗法提供前所未有的可能性 [10]。
在药物发现早期阶段,AI的应用显著提升了效率。靶点识别是药物研发的首要环节,AI通过对海量生物医学数据(如多组学数据)的挖掘与分析,能够快速准确地识别与疾病相关的分子模式和因果关系,精准定位潜在的药物靶点,从而大大缩短发现时间 [33,35,40]。AlphaFold等模型能够快速准确预测蛋白质三维结构,帮助研究人员识别潜在的药物靶点 [8,14,30]。例如,PandaOmics平台整合多组学数据和生物网络分析,成功识别TRAF2和NCK相互作用激酶作为抗纤维化治疗的潜在靶点 [33]。AI在治疗领域与靶点选择中发挥关键作用,能够综合大量复杂数据,且对错误具有相对容忍性 [36]。LLMs在基因优先排序和药物-靶标交互检测方面也展现出应用价值,能够提升分子研究效率 [22]。
虚拟筛选是利用计算方法预测化合物与靶点结合亲和力,AI的应用提高了预测的准确性和效率 [25]。AI驱动的受体-配体对接模型可以预测配体的空间变换,甚至生成复杂原子坐标 [33,40]。Atomwise公司的AtomNet技术利用深度卷积神经网络预测小分子与蛋白质的结合亲和力,是该领域的典型案例 [35]。大模型通过预测药物分子的生物活性,提高了药物筛选的效率和成功率 [37]。
药物从头设计与生成是指自主创造新的化学结构以满足特定分子特征,深度学习是其核心技术,显著提高了效率和新化学结构的识别能力 [25,40]。分子生成模块通常采用化学语言模型或基于图的模型 [25,33,40]。PocketFlow模型基于蛋白质口袋条件,成功生成针对HAT1和YTHDC1靶点的活性化合物 [33]。ChatGPT经过特定数据集训练,可以生成具有相似特征的新型化学结构 [3]。AlphaFold 3等最新模型具备药物设计能力,通过预测分子与蛋白质的结合方式来辅助设计 [19]。AI还能通过模拟药物与生物体的相互作用过程,为药物设计提供更精准的指导和优化建议 [38]。DynamicBind等模型考虑蛋白质动态变化,为药物设计提供了新的范式 [17]。ChemCrow作为LLM化学代理,通过集成工具辅助完成药物发现任务 [3]。
药物在体内过程的评估至关重要,ADMET(吸收、分布、代谢、排泄、毒性)预测是决定药物疗效和安全性的关键环节 [40]。深度学习已成为ADMET预测的核心技术,多种神经网络架构被广泛应用 [25,40]。图神经网络由于融入几何信息,在ADMET预测中表现更优 [33]。拜耳的计算机模拟ADMET平台利用机器学习技术确保预测准确性 [33]。ChatGPT也可以预测新药的药代动力学和毒性作用 [3]。
化学合成是药物发现的另一瓶颈,AI通过计算机辅助合成规划(CASP)和自动化合成技术提供了有力支持,减轻了化学家的重复性劳动 [25,40]。AI驱动的设计-制造-测试-分析(DMTA)平台结合深度学习和微流控芯片化学合成,已成功生成肝X受体激动剂 [33]。AI可以帮助找到一条全局最优的药物研发路线,提高效率 [16]。晶泰科技通过AI预测算法协助辉瑞确认Paxlovid优势晶型,加快了研发 [16]。
除了上述阶段,AI还在其他重要领域展现潜力。生物标志物发现方面,AI能够分析复杂数据,识别与疾病或药物反应相关的关键生物标志物 [39]。**药物重定位(或药物再利用)**方面,AI能够发现现有药物在治疗其他疾病上的潜在新用途,特别是在罕见病或复杂疾病的治疗上,这能大大缩短药物上市时间并减少研发成本 [39]。哈佛医学院的TxGNN模型专门用于零样本药物再利用预测 [32]。LLMs如LEDAP模型也可以预测药物-疾病关联 [32]。
在药物开发的临床阶段,AI的应用也日益深入。AI可以通过分析患者数据,辅助设计临床试验方案,选择合适的患者群体,优化给药剂量和疗程,从而提高临床试验成功率 [35]。太美医疗科技的文思智能平台基于专业知识和临床研究经验,为AI临床试验服务提供支持 [12]。报告指出,用于临床试验的大模型需要具备实时数据处理、伦理合规、风险预测和决策支持能力 [12]。英国Exscientia公司开发的DSP-1181是全球首个由AI设计的进入临床试验阶段的分子 [35]。AI甚至可以用于预测药物释放和与辅料的相互作用,使开发的最后阶段更加系统化 [36]。AI在药物研发的各个阶段均有渗透,包括药物发现、临床前研究、临床试验以及上市后的真实世界研究 [12]。
总而言之,AI/LLM在药物发现与开发全流程的应用展现出巨大的价值,特别是在降本增效方面,能够显著缩短研发周期和降低成本 [5,16,35]。在精准医疗方面,深度学习通过分析患者数据预测药物疗效和副作用,提供个性化用药建议 [43]。佛罗里达大学和德克萨斯大学的DrugFormer模型能高精度预测单细胞水平的药物耐药性 [32]。AI也在推动技术创新,例如蛋白质结构预测的重大突破助力新药研发 [28]。薛定谔公司利用基于物理模型的AI技术在药物分子设计和优化方面取得显著成果 [35]。
尽管AI在药物研发领域取得了显著进展,但仍面临诸多挑战。生物大模型在药物研发领域尚未实现颠覆性突破,仍处于技术融合与场景适配的渐进式创新阶段 [12]。AI药物研发能力验证仍在进行中,企业更倾向于为具体的价值结果付费 [12]。现阶段研究面临的挑战包括对药物研发各阶段应用方法、具体案例、比较优势和特定挑战的详细阐述不足,以及对AI制药市场规模、价值以及面临的技术、数据、法规、临床试验和人才等具体挑战的讨论有限 [22,28,31]。未来的研究需要更系统地探索AI/LLM在各阶段的应用细节,积累更多成功案例,并深入分析其面临的实际挑战,以推动AI在药物发现与开发领域实现更广泛和深入的应用。
3.3 基因组学与组学研究
高通量测序、质谱和成像等现代技术产生了大规模且高精度的多模态生物医学数据[39]。这些数据涵盖了基因组学、转录组学、蛋白质组学和代谢组学等多个组学层面[39]。然而,由于数据类型的异构性、多维度以及海量体量,对这些数据进行有效整合和解释需要消耗大量计算资源,并依赖专门的算法[39]。人工智能,特别是深度学习技术,在处理和分析这些复杂、非结构化及海量数据方面展现出巨大潜力[39,43]。深度学习能够发现多组学数据中的非线性和多维关系,从而更全面地探索生物表征,并深入解释复杂的生物学机制[39]。
深度学习方法在基因组学领域拥有广泛的应用场景,包括基因测序数据分析、疾病相关基因和变异位点挖掘、疾病风险预测以及单细胞数据分析等[23,43]。常用的深度学习方法包括监督学习、多任务学习、迁移学习和无监督学习[23]。例如,深度学习能深入挖掘基因组数据中的复杂模式,并识别与特定遗传病相关的基因变异,从而辅助遗传性疾病的诊断[43]。
近年来,生物科学大模型在基因组学与组学研究中展现出强大的能力和应用潜力[32]。在基因组序列注释和生成方面,斯坦福大学Brian L. Hie团队提出了多模态基因组基础模型Evo,该模型采用Hyena结构而非传统的Transformer结构进行建模,尤其适合处理长序列数据[32]。在病毒发现领域,中山大学与阿里云合作开发的LucaProt深度学习模型整合了序列与结构信息,成功从大规模宏转录组样本中识别出大量全新的RNA病毒,显著扩展了已知病毒种类库[32]。针对单细胞组学数据分析,多伦多大学与微软研究院学者构建了基于生成式预训练Transformer的单细胞RNA-seq基础大模型scGPT[32]。
除了上述特定模型,通用大型语言模型(LLMs)也在基因组学研究中得到应用。例如,仅编码器架构的scBERT和BioBERT已被用于基因嵌入和生物医学文本挖掘[22]。编码器-解码器架构的GeneCompass模型则用于解析基因调控机制[22]。大语言模型还在基因优先排序方面显示出价值[22]。GeneGPT是一种利用LLM通过NCBI Web API回答基因组学问题的新颖方法,并在相关数据集上取得了良好表现[3]。此外,有研究表明,在生物信息学教育中使用ChatGPT辅助学生生成科学数据分析代码是可行的[3]。利用最初为自然语言处理开发的机器学习技术,科学家也成功识别人类肠道微生物基因组序列中编码的抗菌肽[10]。
大模型能够对大规模基因测序数据进行深入分析,高效挖掘与疾病相关的关键基因和变异位点[38,43]。通过构建基于大模型的疾病预测系统,可以实现对疾病风险的早期预警和精准预测[38,43]。研究人员能够分析大规模基因组数据,并结合环境因素、生活方式等多种因素构建疾病风险预测模型,为疾病的早期预防与干预提供科学依据[43]。多模态AI通过整合多组学数据、临床数据(如血常规、生化检查)、文本信息(如电子健康记录)以及影像数据(如超声、CT、MRI)等多种形式的生物医学数据,构建复杂的算法模型,用于识别关键生物标志物、预测疾病风险,并为个体化治疗提供支持[31,39]。在非编码RNA领域,深度学习模型DeepCas13用于建模CRISPR-Cas13d的靶内与靶外效应,并在非编码RNA导向预测上表现出良好性能[1]。研究发现,与靶内效率相关的特征与决定靶外效应的特征十分相似[1]。在mRNA与siRNA设计优化方面,现有算法已能协同优化编码区与非编码区,以提高稳定性、表达量、靶向性和静默效率,这对提升相关药物的疗效及降低毒性具有潜在价值[16]。例如,算法Linear Design仅需较短时间即可生成编码SARS-CoV-2刺突蛋白的最佳mRNA序列[42]。
尽管生物科学大模型在基因组学和组学研究中取得了显著进展,但在具体模型的应用案例、性能指标以及不同深度学习方法优缺点的对比上仍需更详细阐述[22,31]。同时,处理多模态异构数据所需的大量计算资源和特定算法仍是亟待克服的挑战[39]。未来的研究方向将包括更深入地探索新型大模型架构在各类组学数据中的适用性、开发更高效的多模态数据整合方法,以及建立全面的基准测试体系以评估不同模型在特定基因组学任务中的表现。
3.4 临床诊断与个性化医疗
大语言模型(LLMs)以及更广泛的人工智能(AI)大模型在临床诊断和个性化医疗领域展现出巨大的应用潜力,有望显著提升医疗服务的质量和效率[22,38,39]。这些模型的核心优势在于能够整合和分析来自多源的复杂生物医学数据,并在此基础上提供诊断建议和制定个性化治疗方案[22,38,39]。特别地,医疗大模型在语言理解和多模态数据处理方面的进展,正有力推动其在辅助诊断和临床实践中的应用[7,12]。
在诊断辅助方面,大模型能够处理和分析广泛的患者数据,包括结构化病历、医学报告、文本描述的临床症状以及可穿戴设备获取的数字生物标志物[3,25,39]。通过自然语言处理能力,LLMs可以从文本中提取相关信息并进行结构化呈现,甚至帮助研究人员创建新的假设并开发临床决策支持系统[3]。例如,GPT-4在肿瘤学和神经外科场景中的诊断准确度已被报道可与高级医生相当,显示了其在临床诊断与决策支持中的潜力[22]。此外,医疗大模型在临床专病辅助决策、预问诊、病历辅助生成等方面也已得到应用[12]。
医学影像分析是AI在诊断领域应用最为成熟的方向之一[12]。大模型能够实现对医学影像数据的自动解读和分析,快速准确地识别病变区域和异常表现,为医生提供及时准确的诊断支持[38]。通过采用先进的数学算法,如灰度共生矩阵、基于直方图的特征、卷积神经网络和数据增强算法,AI能够对MRI、CT、PET扫描、胸部X光片、超声和病理图像等高维特征进行定量分析,其流程涵盖图像采集、预处理、分割、特征提取及模型验证,显著提高了疾病诊断的速度和准确性[39]。例如,谷歌DeepMind开发的AI系统在眼部疾病诊断方面达到了与专业眼科医生相当的准确率[35]。哈佛医学院团队开发的CHIEF模型能在19种癌症类型中执行多种任务,检测准确率接近94%[32]。深度学习在医学影像识别中能够识别微小病灶、区分肿瘤类型、减少人为判读的主观性,同时也扩展到眼科疾病(如糖尿病视网膜病变)、血管病变和脑部疾病(如脑肿瘤、脑卒中、阿尔茨海默病)的诊断[43]。此外,深度学习支持多模态影像融合分析,并能自动生成初步诊断报告以减轻医生负担[43]。
在个性化医疗方面,AI和大型模型通过整合患者基因组、表型、环境因素、临床数据和生活习惯数据等信息,为个体化治疗提供重要依据[31,39]。通过对基因数据进行分析,AI可以预测患者对特定药物的不良反应[35]。AlphaFold通过预测个体患者蛋白质结构,有助于揭示疾病分子机制,并为制定更精准的治疗方案提供依据[30]。DeepCas13作为一种预测方法,有助于设计基于CRISPR-Cas13的高效基因疗法系统,以靶向RNA治疗多种人类疾病[1]。AI还能优化剂量-反应关系,提升药物安全性,并精细调整治疗窗口,为个体化用药提供支持[25]。多模态AI技术能够基于多模态数据生成更准确的预测模型,为患者提供个性化治疗方案,其涵盖疾病早期诊断与风险预测、患者精准分层与预后评估、复杂疾病遗传与风险因素分析以及临床治疗方案响应预测等方面[39]。例如,Tempus公司利用AI分析肿瘤患者数据,为肿瘤药物临床试验提供精准的患者分层和入组建议[35]。在临床试验监测中,AI能够通过医疗记录、可穿戴设备数据和问卷数据监测患者情况、识别不良事件或确定试验结果[39]。PathChat作为面向医学领域的多模态AI助手,能够理解和分析医学图像,并基于文本对话提供个性化的病理学指导[32]。
尽管AI和大型模型在临床诊断和个性化医疗中已取得显著进展,但仍存在挑战与研究空白。例如,尽管ChatGPT在预测药物相互作用方面部分有效,但有时提供的信息不够完整,需要进一步改进[3]。处理医学伦理和数据隐私问题仍是LLMs应用中亟待改进的方面[22]。此外,一些现有文献仅简要展望了AI在疾病治疗方面的潜力,而未深入探讨大模型在临床诊断、个性化治疗方案制定、临床试验等方面的具体应用案例、模型、优势与局限性[28,31]。对于Med-PaLM2、MedGemini、LLaVA-Med等特定医疗大模型的特点和功能,现有研究的着墨相对不足[22,31]。未来的研究需聚焦于提升模型的准确性、可靠性与泛化能力,解决数据偏差和可解释性问题,并建立完善的伦理与监管框架,以确保AI模型在临床实践中安全且有效地应用。同时,探索多模态AI模型在整合不同类型生物医学数据以实现更精准诊断和个性化治疗方面的潜力,以及其在辅助医生进行决策而非取代医生中的角色定位,将是未来研究的重要方向[43]。
4. 大模型在材料科学领域的应用
| 挑战维度 | 具体挑战表现 | 应对途径/解决方案 |
|---|---|---|
| 数据基础设施 | 尚不完善 | 加强基础设施建设 |
| 实验数据处理 | 数据稀疏、高维、有偏差、噪声,影响MI模型性能 | 提升数据质量与多样性;利用领域知识弥补数据不足 |
| 数据质量/数量 | 低质量数据影响预测精度;数据量不足限制模型训练 | 标准化和共享数据资源;构建全球化数据共享平台;推动实验/计算数据标准化 |
| 泛化能力 | 模型可能过度依赖特定数据集 | 提升模型泛化能力 |
| 逆向设计 | 基于期望性能逆向设计材料需要高效算法 | 开发先进的MI算法 |
人工智能(AI)和大模型(LLM)正深刻变革材料科学的研究范式,加速并优化了材料的研发、发现与应用过程。传统的材料研发高度依赖实验驱动的“试错式”方法,往往耗时漫长且成本高昂[44]。AI技术的引入,凭借其强大的数据分析能力和机器学习算法,为材料研发带来了革命性的变化,显著提升了新材料的开发效率[29,45]。AI不仅能够快速分析海量实验数据和计算数据,发现分子结构和属性之间的相互关系,为材料设计提供指导[45],更能预测新材料的特性与性能,从而极大地缩短新材料从理论到实际应用的时间[29,45]。
这一变革的核心在于从传统的经验驱动转向数据驱动的新范式,即材料信息学(Materials Informatics, MI)的兴起[9,44]。美国提出的“材料基因组计划”(MGI)正是这一趋势的重要体现,旨在通过高通量计算、大数据和AI等技术,解码材料组成与性能间的对应关系,有效缩短研发周期、降低研发成本[15,44]。例如,美国国家标准与技术研究所(NIST)开发的CAMEO AI算法已展示了自主发现潜在实用新材料的能力[45]。在大模型和生成式AI的推动下,材料发现进入了新的阶段。例如,DeepMind的GNoME模型通过高通量计算预测了大量稳定的晶体材料[7,9],微软的MatterGen模型能够按需预测新材料结构[9],生成对抗网络(GAN)等技术也被用于在虚拟环境中创造新的化合物结构并预测其表现[11,29]。这些进展共同构成了AI赋能材料科学研究的强大引擎,正在重塑材料研发的未来范式[9]。
4.1 数据驱动的材料发现与材料信息学
数据是新材料研发的基础[44]。传统的新材料研究范式主要依赖于实验驱动的“试错式”方法,通过反复尝试不同的成分、合成方法和工艺参数来寻找性能最佳的材料[44]。这一范式正逐步向数据驱动转型,材料信息学(MI)应运而生[9]。
材料信息学利用以数据为中心的方法推进材料科学研究,其目标在于设计新材料、发掘特定应用领域中的材料并优化材料处理方式[9]。MI不仅具备预测给定材料特性能力,更重要的是能够基于期望的材料性能进行逆向设计[9]。这种数据驱动模式显著缩短了传统材料设计中耗时且成本高昂的实验试错和重复搜索过程,极大提升了研发效率[9]。
然而,材料信息学的发展面临诸多挑战。其中,一个关键问题在于数据基础设施尚不完善[9]。此外,MI算法在处理实验数据时往往显得不足,因为实验数据普遍存在稀疏、高维、有偏差和噪声等问题[9]。这种低质量数据严重影响了MI模型的性能和预测精度。
应对这些挑战的途径包括加强数据基础设施建设以及提升数据质量。未来的研究与实践应着重推动数据资源的共享与标准化[45]。具体而言,需要构建全球化的材料数据共享平台,并积极推动实验数据与计算数据的标准化工作[45]。标准化和共享的数据资源对于提升AI模型的预测精度至关重要[45],有助于克服当前数据稀疏和质量不足的问题。在应对数据挑战时,充分利用领域知识也被视为大多数方法的重要组成部分,有助于弥补数据本身的不足[9]。
4.2 AI模型与自动化实验在材料科学中的应用
人工智能(AI)模型正深刻变革材料科学的研究范式,显著提升了材料设计、发现、合成与测试的效率与智能化水平。在材料设计阶段,AI已成为核心驱动力,能够设计出具有特定功能的智能材料,并实现材料的定制化生产 [29]。研究人员可以利用AI技术筛选海量的材料组合,例如在耐蚀材料研发中,AI能够辅助科学家从成千上万种潜在配方和工艺中快速识别最优方案 [44]。
不同AI模型在材料科学中展现出多样化的应用潜力。例如,在材料性能预测方面,利用不同的腐蚀预测模型对材料进行仿真测试,可以快速评估材料在高温高湿、强辐射或微生物环境等复杂工况下的服役效果、耐蚀性及预期寿命 [44]。这极大地压缩了传统的试错周期。在材料配方的优化过程中,强化学习(RL)等方法扮演了重要角色。以Epsilon-Greedy策略为例,该策略通过平衡探索未知空间与利用已知最优策略来实现优化,初始阶段设置较高的探索率以充分探索决策空间,随后逐渐降低探索率,使得模型能够随着对决策空间的深入了解而转向利用 [9]。这些AI模型的应用显著提高了材料研发的效率和成功率。
AI与自动化技术的结合催生了AI驱动的机器人实验室,这些系统能够自动化执行材料合成与测试流程 [45]。通过实时数据反馈,这些实验室能够持续优化实验参数,从而提高实验效率和精度 [45]。机器人实验室与AI决策系统的融合,使得材料性能测试能够实现24/7不间断运行,极大地提升了研究效率 [5]。这种模式正在推动“自我驱动实验室”的兴起,这些实验室能够利用AI算法优化实验设计和数据分析流程,实现更高效的科学探索 [45]。最终目标是构建一个集材料设计、合成、表征与优化于一体的自主研发闭环系统,实现完全自动化的材料研发流程,彻底革新传统材料研究的模式 [45]。支撑这些先进应用的基础设施,如材料基因工程先进计算平台,对于推动材料科学的创新变革至关重要 [44]。
5. 大模型在其他科学领域的应用
| 科学领域 | 典型应用与突破 | 关键技术/模型示例 |
|---|---|---|
| 数学 | 求解偏微分方程;发现数学定理 (Knots);发现更优算法 (矩阵乘法, 排序);解决几何问题 (IMO) | 机器学习, ResNet, seq2seq, AlphaTensor, AlphaDev, AlphaGeometry |
| 物理学 | 高能物理数据处理 (粒子识别);托卡马克等离子体控制;寻找新物理迹象 (隐性内含粲夸克);天体物理 (识别星系/天体);粒子物理理论预测 | 人工神经网络 (ATLAS), 深度强化学习, Modulus物理-机器学习模型, AI+量子计算 |
| 地球科学 | 提高天气预报准确性;预测气候变化/极端天气/自然灾害;模拟生态系统行为 | AI天气预报模型, 自然灾害模型, Aurora大气AI基础模型, FourCastNet, 生物科学大模型 |
| 分子动力学 | 将模拟规模扩展至10亿原子量级并保持高精度 | DeePMD-kit (机器学习+高性能计算+物理建模) |
| 工业领域 | 流体/结构等偏微分方程求解;知识嵌入/发现在力学/能源等应用 | 数据与物理机理融合AI方法, 知识图谱技术 |
| 生物制造 | 研发更高效率的工业酶 | AI大模型 |
| 脑机接口 | 无创方法 (无声语音识别);增强可植入接口解码性能 | AI技术 |
大型模型及相关人工智能技术的突破性进展,正在以前所未有的方式加速并赋能多个科学领域的研究与发展。这些技术不仅在生命科学等备受关注的领域取得了显著成就,其影响力正逐步扩展至数学、物理、地球科学及其他交叉学科,推动解决长期以来难以克服的复杂科学难题。
在数学领域,人工智能的应用已展现出强大的问题解决能力。自2017年起,研究人员开始尝试利用机器学习、ResNet、seq2seq模型等技术求解偏微分方程,并取得了速度更快、精度更高的结果[7,15]。DeepMind在数学定理证明和算法优化方面做出了一系列贡献,例如在2021年开发机器学习框架,启发数学家发现了Knots理论的新定理,并证明了已提出40年之久的Kazhdan-Lusztig多项式[7,15]。2022年10月,DeepMind推出的AlphaTensor通过强化学习发现了矩阵相乘的最快算法[7,15]。随后,AlphaDev于2023年6月被推出,用于发现更高效的排序算法[7]。此外,DeepMind与纽约大学合作开发的AlphaGeometry在国际数学奥林匹克竞赛(IMO)几何题上的表现与人类金牌得主相当,能够解答30道题目中的25道[7],凸显了人工智能在解决复杂几何问题方面的潜力。
物理学领域是人工智能应用较早的科学分支之一。高能物理和核物理学界自20世纪90年代起就已开始使用人工智能,主要用于处理大型强子对撞机(LHC)等实验产生的大量异构数据,以加速科学发现[7,15]。例如,人工神经网络在2014年的ATLAS实验中成功识别了希格斯玻色子[7,15]。欧洲核子研究组织(CERN)于2015年成立了机器学习工作组专门应对海量数据挑战[15]。近期进展包括DeepMind在2022年通过深度强化学习对托卡马克等离子体进行磁控[7,15],以及物理学家利用神经网络找到了质子中存在隐性内含粲夸克的证据[7,15]。在天体物理学方面,AI已能从海量图像中识别新的星系和天体,为宇宙演化研究提供数据[5]。结合量子计算,AI在粒子物理理论预测方面也显示出潜力[5]。英伟达开发的“Modulus物理-机器学习模型”开源框架在同精度级别下实现了3~5个数量级的加速效果[7]。
气象学、海洋学、大气科学和气候科学等地球科学领域也广泛引入了人工智能建模方法。AI被用于提高天气预报的准确性,以及预测海平面上升、气候变化、极端天气和自然灾害等复杂环境现象[7]。具体应用包括谷歌公司推出的人工智能天气预报模型和自然灾害模型[7],以及微软公司推出的首个大气人工智能基础模型Aurora,能够准确预测全球天气和空气污染[7]。此外,基于新型算子学习的神经网络模型FourCastNet能够将天气预报速度大幅提升至45000倍[10]。在生物科学领域,生物科学大模型也被应用于模拟生态系统行为,以支持生态保护与恢复工作[31]。这些模型通过融合数据与物理机理,在处理复杂的物理和环境问题中展现出优势。
除上述领域外,人工智能的应用正渗透到更多科学和工程分支。在分子动力学领域,DeePMD-kit项目通过机器学习、高性能计算与物理建模结合,将模拟规模扩展至10亿原子量级并保持高精度,解决了传统方法在速度和精度上的矛盾[10]。工业领域的流体、结构等偏微分方程求解问题,基于数据与物理机理融合的AI方法已被证实是解决复杂高维问题的有效途径[10]。知识嵌入和知识发现的进展也为力学和能源等工业领域带来潜在发展机遇[20]。生物制造领域,AI大模型的技艺突破有助于研发更高效率的工业酶[28]。在脑机接口领域,AI的进步使得创新的无创方法如无声语音识别设备成为可能,并能增强可植入接口的解码性能,对恢复神经功能具有重要意义[36]。在生物技术和药物研发的交叉领域,如CancerGPT这样的少样本学习模型利用大型语言模型预测稀有组织中药物对的协同作用[3]。为支持跨学科的AI科研,部分机构已着手搭建AI for Science科学数据开放平台及相关的科学大模型[18]。这些广泛的应用案例表明,AI大模型正成为驱动多个科学领域研究范式转变的关键力量。
6. 大模型驱动科学发现的关键技术与方法
本节深入剖析支撑大模型驱动科学发现的关键技术和方法。科学发现的核心在于提出并验证科学假设,传统方法在面对海量复杂数据时效率受限 [36]。人工智能的出现,特别是大语言模型(LLMs),正为科学研究的各个环节带来变革,并赋能全新的研究范式 [41]。AI驱动的科研范式通过对海量数据的收集与处理并进行智能模型训练,赋能科研多场景,嵌入科研全过程 [13]。本章将系统梳理大模型驱动科学发现所依赖的关键技术与方法,涵盖从基础的假设生成到智能化的实验执行与系统构建。首先,我们将聚焦于AI如何辅助科学假设的生成与优先排序,探讨基于文献、数据以及文献数据融合等多样化的方法 [27],并分析如基于文献的发现(LBD)与归纳推理等传统范式在AI加持下的演进 [2],以及Bit-Flip等新方法的潜力 [6]。随后,将进一步阐述支撑自动化和智能化科学发现流程的关键组件和系统。
6.1 AI辅助的科学假设生成
科学假设的生成与优先级排序是科学发现过程中的核心环节[36]。传统上,科学假设的形成主要依赖研究人员的理论知识、经验积累以及对现有文献的深入分析。然而,随着数据量的爆炸式增长和研究领域日益复杂,人工生成假设的效率和广度面临挑战。人工智能技术,尤其是大语言模型(LLMs),为加速和增强科学假设生成提供了全新途径。AI可以通过分析现有文献、识别研究空白,并依据数据趋势预测潜在的相关性和因果关系,从而辅助生成科学假设[41]。例如,在健康研究中,AI能够根据患者数据的变化趋势预测新治疗方法可能带来的疗效[41]。
目前,AI辅助科学假设生成的方法呈现多样化,主要包括理论驱动、数据驱动以及文献数据融合等范式[27]。传统的理论驱动方法高度依赖高质量的文献资源,难以有效应对新产生的数据,且缺乏现实数据支持,可能导致假设与实际情况不符[27]。相比之下,数据驱动方法侧重从大规模数据中挖掘模式,但同样存在过度依赖特定数据集、泛化能力不足的问题[27]。
文献驱动的方法中,基于文献的发现(Literature-Based Discovery, LBD)是一种重要范式[2]。LBD的核心思想源自Swanson,认为知识可能已公开分散在不同文献中,但尚未被关联和发现,即“如果独立创建的片段在逻辑上相关却从未被检索、汇总和解释,则这些知识虽公开却未被发现”[2]。Swanson提出的经典“ABC”模型形式化了LBD:如果概念A和概念C都在论文中与中间概念B共同出现,则可以假设A与C之间存在潜在关联[2]。传统的LBD主要侧重于预测关系,而Wang则尝试将LBD置于自然语言语境中,并通过生成完整句子作为输出,而非仅仅预测关系,这为利用自然语言处理技术改进LBD奠定了基础[2]。研究表明,在社会科学和化学领域,许多已发表的假设可以通过LBD模式构建,从而显示出其广泛适用性[2]。
归纳推理则是另一种重要的假设生成范式,其过程是从具体观察中抽象出具有广泛适用性的规则或假设[2]。Yang首次在自然语言处理领域探索生成式归纳推理,利用语言模型从具体的自然语言观察中提取自然语言规则,并引入科学哲学中对归纳推理的要求,这标志着将LLMs应用于归纳推理生成假设的早期尝试[2]。
针对传统方法的局限,研究者提出了文献数据融合的假设生成方法[27]。该方法旨在整合文献中的洞见与数据中的模式,以生成更全面、有效且泛化能力更强的假设[27]。有研究团队提出首个将文献信息与现实观察数据相结合,并利用大模型驱动假设生成的方法,通过协作机制使文献驱动和数据驱动方法在假设生成与更新中相互补充,从而显著提升了假设生成的效率和实用性[27]。
在具体的AI模型应用方面,Bit-Flip方法结合LLM的研究展现出巨大潜力[6]。Bit-Flip方法可以理解为一个从初始信息(Bit)到核心见解或假设(Flip,也称Spark)的思维过程,并包含从Bit到Flip的推理链(Chain-of-Reasoning)[6]。HypoGen数据集为研究Bit-Flip过程提供了宝贵资源,该数据集包含了从计算机科学会议论文中提取的Bit、Flip、Spark和推理链等数据项,共计5000余组,并利用OpenAI的o1模型进行提取[6]。研究表明,经由HypoGen数据集微调后的LLaMA模型能够根据输入的Bit信息生成相应的Spark和推理链信息[6]。这一实验结果验证了LLM在捕捉并复现人类从背景信息中提炼科学假设及其推理过程方面的能力。
评估AI生成假设的质量是该领域面临的关键挑战。不同的评估方法关注假设的不同属性,例如与现有知识或数据的一致性、生成假设的多样性、新颖性以及可行性等。在这些评估指标之间往往存在权衡关系:高度新颖的假设可能初期难以验证其可行性,而与现有知识高度一致的假设可能缺乏新颖性。如何在对齐性与多样性、新颖性与可行性之间取得平衡,是AI辅助假设生成方法亟待持续探索的问题。
总而言之,AI,尤其是LLMs,通过改进现有方法(如LBD、归纳推理)并赋能新的范式(如文献数据融合、Bit-Flip),正在显著提升科学假设生成的效率和质量。LLMs强大的自然语言处理与生成能力使其能够更好地理解和综合复杂的文献与数据信息,并以自然语言形式输出假设及其推理过程。然而,如何设计更为高效的融合策略、提升生成假设的可控性以及建立全面可靠的评估体系,仍然是未来研究亟待解决的重要问题。
6.2 科学发现方法的关键组件与发展
大模型驱动的科学发现方法呈现出一种显著的发展趋势,即通过不断纳入更多关键组件以系统性地提升研究过程的效率与质量 [2]。这些关键组件共同构建了一个更为全面和鲁棒的科学发现框架。根据现有研究,主要的组件包括灵感检索策略、新颖性检查器、有效性检查器、清晰度检查器、进化算法、多重灵感的利用、假设排序以及自动研究问题构建 [2]。对这些组件的详细分析有助于理解当前科学发现方法的运作机制及其发展方向。
灵感检索策略是科学发现流程的起点,旨在为假设生成提供初始概念或信息来源。SciMON首次将基于文献的发现(LBD)概念引入此类任务,其核心思想是通过挖掘现有知识之间的关联来发现潜在的新知识 [2]。MOOSE法则提出利用大语言模型(LLM)从给定的候选列表中选择与特定研究背景高度相关的灵感 [2]。另一项研究通过构建HypoGen数据集并对LLM进行微调,利用对大量文献中Bit和Flip信息的分析作为灵感来源,构建了一种灵感检索的实现方式 [6]。这些策略共同促进了从海量信息中提取有价值的发现线索的能力。
反馈模块,包括新颖性检查器、有效性检查器和清晰度检查器,在假设生成后的迭代优化过程中发挥关键作用。新颖性检查器评估生成假设的原创性;有效性检查器则侧重于评估假设的科学合理性和可行性;清晰度检查器关注假设表述的准确性和易理解性。MOOSE方法提出了基于这些维度的迭代反馈机制,以循环改进生成的假设质量 [2]。例如,HypoGen生成的新假设需要通过后续的评估方法进行新颖性检查 [6]。这些检查器的贡献在于为生成的假设提供了多维度的质量控制和精炼指导。
进化算法作为一种优化工具,也被引入到科学发现任务中,以优化假设生成过程。FunSearch首次将进化算法应用于此领域,采用基于岛屿的进化算法 [2]。在此框架下,每个“岛屿”代表一组相似的假设或方法,它们通过变异等操作产生新的假设,并通过选择机制保留和优化更优的假设。进化算法的优势在于其强大的搜索和优化能力,能够在大规模假设空间中系统性地探索并发现潜在的优秀假设。
利用多种灵感是提高假设质量和完整性的重要途径。MOOSE-Chem首次引入了这一组件,其动机在于许多学科的完整且可发表假设往往需要整合来自多个源头的灵感 [2]。这种方法显著提高了生成假设的全面性和深度。与此相关的文献数据融合策略,例如精炼生成(在数据驱动假设基础上融入文献洞见进行多轮迭代)和合并生成(分别生成基于文献和数据的假设集后合并),也体现了整合不同信息源以提升假设质量的思路 [27]。
假设排序组件用于对生成的假设进行优先级评估。大多数现有方法采用LLM对假设的评分作为奖励值,据此对假设进行排序 [2]。这有助于研究人员快速筛选出最有潜力的研究方向。
自动研究问题构建是实现科学发现流程全自动化的关键步骤。MOOSE引入了“全自动驾驶”模式,通过基于LLM的智能体持续搜索网络语料库,自主识别有趣且与学科相关的研究问题 [2]。这一组件旨在自动化科学研究的初始阶段,进一步解放研究人员的时间。
这些关键组件的发展和整合,标志着大模型驱动的科学发现方法正从简单的假设生成向更全面、包含评估、优化和自动化的复杂流程演进,从而更有效地辅助甚至主导科学新知的发现。
6.3 智能化科学设施与自主发现系统
智能化科学设施与自主发现系统是当前大模型驱动科学研究范式变革的核心组成部分。这些设施旨在通过深度整合人工智能、机器人技术、先进计算和数据资源,构建高效、自动化、智能化的科研环境,从而极大地加速科学发现过程。
上海交通大学人工智能研究院 AI for Science 团队提出了智能化科学设施的构想,该构想包含四大创新功能,共同支撑 AI 驱动的科学研究:
- 科学大模型(科学基础大模型):这类模型旨在辅助人类科学家进行研究,其关键能力包括跨学科知识整合、处理跨模态数据输入、有效调用外部科学工具以及基于反馈与评测持续进化[18]。构建有效的科学大模型需要在基础大语言模型之上发展出特定能力,例如跨学科跨模态统一输入、外部工具调用、模型持续反馈进化以及幻觉消除,并需要相应的评测基准来衡量这些能力[18]。
- 生成式模拟与逆向设计:利用生成式神经网络,可以将复杂的数值求解问题转化为数据拟合,建立假设空间与仿真空间之间的高效映射,从而加速模拟过程[18]。进一步结合生成式渲染技术实现从仿真空间到观测空间的转换,可形成“假设—仿真—观测”的闭环学习,进而驱动科学规律的逆向发现(即逆向设计)[18]。
- 自主智能无人实验系统:该功能将人工智能和机器人技术应用于科学实验,通过无人化、标准化、大规模的实验流程设计与执行,显著提升实验效率和可重复性[18]。这种系统能够实现实验过程的自动控制与自主决策,大幅减少科研人员在重复性实验工作上投入的精力与时间[13]。无人实验操作可覆盖微观与宏观等不同空间尺度[18]。
- 大规模科研协作:智能化设施需要支持安全、高效的数据共享,并建立知识产权保护机制[18]。区块链技术可以提供安全可信的协作基础,联邦学习技术有助于解决数据孤岛问题并保障数据安全和科研效率,而互联网群体智能则能整合不同的科研模块以实现高效协同[18]。这推动了数据与代码共享、信息交互和流程开放,促进了以虚拟实验室和开源平台为代表的“大平台、小用户”新型科研组织模式的发展[13]。
在智能化科学设施框架下,“机器人科学家”的概念及其在加速科学发现中的潜力日益受到关注。通过整合多种智能系统和数据库,可以构建一体化的智能研发平台[11,45],例如松山湖材料实验室开发的 MatChat AI Agent 就整合了“机器人材料科学家”与材料科学数据库[11,45]。这种自动化和自主决策能力增强了科研仪器设备的功能,并促使科研人员重新定位人机分工模式[13]。未来的目标是构建集材料设计、合成、表征与优化于一体的自主研发闭环系统,实现完全自动化的科学研发流程[11]。
在实现智能化科学设施和自主发现系统的过程中,多项关键技术发挥着核心作用,同时也面临相应挑战。人工智能代理模型(AI Agent),作为执行特定任务的智能实体,是构建“机器人科学家”和自主实验系统的基础[11,45]。基础模型(Foundation Models),尤其是面向科学领域的科学大模型,为理解复杂科学现象和辅助研究提供了通用能力,但其在跨模态处理、外部工具调用、持续进化和幻觉消除等方面仍需进一步探索[18]。逆向设计作为生成式模拟与逆向设计关键环节,通过闭环学习驱动规律发现,是加速新材料、新药物等研发的重要技术方向[18]。尽管数字孪生、人工智能编程和软件工程等技术也在推动科研效率和探索新架构方面显示出重要作用,但其在智能化科学设施和自主发现系统构建中的具体应用和面临的挑战仍有待进一步阐述和研究。
当前研究面临的挑战包括如何构建真正具备通用性和鲁棒性的科学基础大模型、如何实现跨尺度和跨领域的自主实验操作、如何保障大规模科研协作中的数据安全和知识产权以及如何有效整合不同智能模块以形成无缝的自主发现闭环。未来的研究方向将聚焦于提升科学大模型的专业能力、发展更高级别的自主决策与实验执行系统、探索更高效和安全的科研协作模式,并最终实现高度自主化、智能化的科学发现新范式。
7. 大模型驱动科学发现面临的挑战
| 挑战维度 | 具体挑战表现 | 影响 |
|---|---|---|
| 数据质量 | 信息缺失、错误、偏见、噪声;实验结果不一致;数据不完整 | 降低AI模型可靠性;放大和固化科学偏见;生成不准确假设/结果 |
| 数据数量/稀缺 | 许多科学领域数据稀缺 (如蛋白质结构, 药物-蛋白质相互作用) | 限制模型有效应用;降低模型泛化能力 |
| 数据隐私/安全 | 包含敏感信息 (如生物医学数据);泄露风险 | 损害患者隐私/权益;限制数据共享 |
| 数据异质性 | 数据来源广泛、格式多样 (实验, 计算, 文献等) | 增加模型训练难度;需要复杂的整合/标准化处理 |
| 数据标准化 | 不同来源数据格式不统一,难以有效整合 | 限制模型利用多源数据 |
大模型技术的迅猛发展正在深刻地重塑科学发现的模式,开启了探索未知和加速创新的前所未有机遇。然而,将大模型高效应用于科研并充分发挥其潜力绝非易事。
 9
9
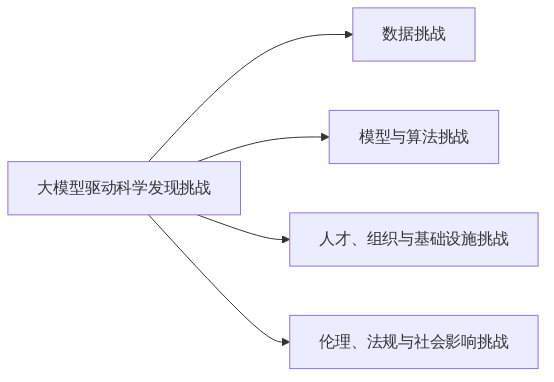
这个进程面临一系列复杂且相互关联的挑战,这些挑战不仅源自技术本身,还涉及数据、人才、组织模式以及伦理法规等多个层面[5,7,20,31,33,35,37,44]。本章旨在对当前大模型驱动科学发现所面临的主要挑战进行系统性分类和深入分析,为理解该领域瓶颈问题提供理论框架。这些挑战主要集中在以下几个核心领域:首先是数据层面,包括数据质量、数据量、多样性、隐私保护和标准化等问题;其次是模型与算法方面,涉及模型的可解释性、准确性、泛化能力、计算效率以及对复杂科学问题的建模能力;再者是人才、组织与基础设施方面,重点关注跨学科人才的培养、科研协同合作模式以及计算与数据平台的支撑能力;最后是伦理、法规与社会影响层面,涵盖数据隐私、算法公平、监管体系建设以及技术应用带来的社会变革。全面认识并有效应对这些关键挑战,对引导大模型技术健康发展和推动科学研究模式向智能化转型具有至关重要的意义。
7.1 数据挑战
大模型在驱动科学发现范式变革的过程中,面临诸多源于数据层面的严峻挑战,这些挑战直接关系到模型的性能、可靠性和泛化能力。数据质量和数量对大模型的表现具有决定性影响[22,31],因此,保障和提升数据的质量和规模至关重要[31]。
当前研究面临的主要数据挑战包括数据质量不足、偏差、噪声和稀缺性。现有数据常常存在信息缺失、错误和偏见等问题[33],例如药物发现实验结果的不一致性以及为节省成本导致的数据不完整,都降低了人工智能模型的可靠性[33]。训练数据的质量直接影响模型的性能和生成结果的事实准确性[6,22]。如果训练数据包含不准确或有偏见的信息,模型输出可能放大和固化现有的科学偏见[5,6],导致生成不准确的假设或结果[6]。此外,许多科学领域面临数据稀缺性问题,例如蛋白质结构数据,人体内存在大量蛋白质,但已解析三维结构的相对较少[28]。药物-蛋白质相互作用等特定数据类型的短缺,限制了模型的有效应用,如AlphaFold在模拟药物-蛋白质相互作用方面的能力[19]。生物学数据普遍存在有限的情况[16]。为应对这些挑战,需要采取策略改进数据质量和多样性。这包括持续改进数据获取技术,提高数据质量和处理效率[37];收集更大规模、更高质量、更具多样性的数据集[22,31];通过自动化或标准化的实验方法提高数据质量并降低获取成本[16];以及利用数据增强和数据混合策略提高模型鲁棒性和性能[22]。开发新的实验方法以增加数据维度也是提升数据价值的重要途径[16]。对于大规模数据,还需要配套有效的数据分析方法,人工智能和深度学习为此提供了新的突破口[10,16]。
数据隐私与安全是大模型驱动科学发现,特别是涉及敏感信息的领域(如生物医学)中的核心关切点[22]。生物医学数据,包括基因组学、蛋白质组学和临床数据等,通常包含患者的敏感信息[35],一旦泄露可能对患者隐私和权益造成严重损害[35]。为了在利用这些宝贵数据的同时保护隐私,研究人员探索了多种技术。联邦学习(FL)作为一种潜在的解决方案被提出,例如OpenFedLLM和FedMed等框架,允许在分布式数据集上进行协同训练,而无需将原始敏感数据集中到一个位置[22]。差分隐私等其他隐私保护技术也在该领域展现出应用潜力。
此外,科学研究领域的数据常表现出高度的复杂性和异质性[37],数据来源广泛、格式多样[35]。这种数据异质性对大模型的训练和应用提出了标准化挑战。不同来源、不同实验方法、不同测量尺度产生的数据需要有效的整合和标准化处理才能被模型有效利用。数据整合和共享对于构建大规模、多样化数据集至关重要,但也面临技术和非技术的阻碍。尽管摘要中未详细阐述数据整合与共享的具体障碍,但广泛的数据来源和多样的格式本身就凸显了标准化和互操作性的必要性。解决这些异质性和标准化问题是充分发挥大模型潜力的关键。
7.2 模型与算法挑战
大模型在推动科学发现过程中展现出巨大潜力的同时,其模型结构和算法仍面临诸多显著挑战,而这些挑战正是制约其性能、可信度及广泛应用的关键因素。
首先,模型的可解释性是当前研究领域的核心难题。许多大型深度学习模型,尤其是大语言模型(LLMs),本质上被视为“黑箱”,其内部复杂的决策过程和预测结果难以被人类理解和解释 [22,37]。这种不透明性与科学研究强调的可重复性和可解释性原则存在冲突 [5],尤其是在生物医学等对可靠性和安全性要求极高的领域,模型决策缺乏透明度严重影响了用户的信任度 [22,37]。因此,发展可解释人工智能(XAI)技术,提升大模型的透明度和可信度,已成为亟待解决的问题 [37]。提高模型可理解性对于确保人工智能生成科学假设的合理性和可验证性至关重要 [6]。同时,人工智能在药物研发领域也面临着模型难以解释决策过程和预测结果的问题 [35]。
其次,模型预测结果的准确性和稳定性仍需进一步提升 [35]。科学大模型有时会输出看似合理但实际上错误的信息,即所谓的“幻觉” [4,18]。例如,在蛋白质结构预测领域,尽管先进模型如AlphaFold 3取得了显著进展,但仍存在局限性,包括在立体化学上不总是遵循手性原则,偶尔产生重叠原子,以及在无序区域生成虚假结构 [4]。此外,确保预测的三维结构遵循基本空间几何规律也是模型和算法面临的重要挑战 [8]。虽然LLMs在某些任务上表现出色,但在复杂任务或缺乏针对性微调的情况下,其准确性可能会受到限制 [22]。虽然摘要中未详述数据偏见和模型过拟合对准确性及稳定性产生的影响,但这些问题普遍存在于各类人工智能模型中,亟需通过有效的模型验证与优化策略加以缓解。
第三,模型泛化能力的局限性制约了其在不同科学领域和复杂场景中的应用。为特定领域或任务设计的人工智能算法可能无法完全适用于其他复杂场景,例如,用于其他领域的算法可能难以应对药物研发中的复杂性 [33]。如何将现有方法有效地应用于不同科学领域仍是一个持续的挑战 [6]。此外,在处理稀有数据或对新颖结构进行预测时(例如,孤儿蛋白预测精度的限制),模型泛化能力面临更大挑战 [31]。为了确保人工智能生成的科学假设在更广泛的背景下保持合理性和可验证性,必须进一步提升模型的泛化能力 [6]。克服现有模型对特定输入(如MSA检索)的依赖,增强对新颖输入的预测能力,是模型和算法未来发展的重要方向 [28]。
第四,尽管摘要中对此讨论较少,但人工智能在预测因果关系方面的困难也是一个重要的算法挑战 [23]。目前的模型更擅长识别相关性,而非因果性,这限制了其在揭示复杂科学机制中的应用潜力。
第五,多模态数据融合是提升模型性能和泛化能力的潜在方向,但在实现过程中也存在诸多挑战。如何将文本、图像、基因序列等多种数据类型有效整合,以提供全面的科学洞察,将成为未来研究的趋势 [22]。然而,开发一种既高效又能充分利用各模态信息的融合技术仍在探索阶段 [22]。
最后,训练和部署大型模型需要消耗巨大的计算资源和能源 [22],这在一定程度上限制了其推广应用 [22,31]。高昂的计算成本不仅提高了研究门槛,还对环境带来了显著影响。为降低计算成本与能源消耗,研究人员正积极探索多种策略,例如参数高效微调(PEFT)方法中的LoRA和QLoRA [22]。
综上所述,大模型在推动科学发现过程中面临的挑战涵盖了模型的可解释性、预测结果的准确性与稳定性、泛化能力、因果关系预测、多模态数据融合以及计算资源需求等多个方面。要克服这些挑战,亟需在算法创新、数据处理技术进步以及软硬件协同优化等方面取得突破,从而提升模型在科学研究中的可靠性和实用性,并促进其更广泛的应用。
7.3 人才、组织与基础设施挑战
人工智能驱动的科学发现(AI4S)新范式的发展,对现有的科研人才、组织模式及基础设施提出了严峻挑战。首先,AI4S领域对跨学科复合型人才存在迫切需求[5,37,42,44]。具体而言,AI制药等前沿领域亟需同时掌握AI技术和医药知识的复合型人才,而目前这类人才相对匮乏[33,35]。在生物医学研究中,需要生物学家、计算机科学家和医学家等领域的专家共同协作[31,37]。材料智能研究(MI)需要弥合材料科学家与数据科学家/工程师之间的知识鸿沟[9]。这种对多学科知识融合的需求凸显了现有教育体系的不足,传统的科研模式以“师傅带徒弟”的作坊模式为主,效率有待提升[10]。为了应对人才挑战,需要建立有效的人才培养体系,培养对基本原理和实际问题均有深入理解的人才[21],并对医疗人员等一线科研人员进行培训,使其了解AI工具的局限性及正确使用方法[22]。高校应积极探索建立跨学科人才培养体系,深化国际合作,以满足AI4S发展的长期需求[5,37,42,44]。
其次,跨学科合作机制的不足严重阻碍了AI在科学领域的广泛应用。推动AI4S发展,需要促进不同学科之间的交流与合作[9,21,37]。这要求科研组织构建垂直整合的团队,使AI研究人员与基础科学领域研究人员能够紧密合作并进行高频率的日常学术交流,同时引入工程化人才,从实际需求出发开发可迭代的工具与软件[21]。加强AI、材料科学与量子计算等领域的交叉合作,通过多学科协同攻关,是解决复杂科学问题的有效途径[45]。此外,传统科研模式与AI驱动模式的融合也面临挑战,传统科学设施和研究范式下存在科学问题沟通难、科学实验操作难、科学数据共享难等固有困难,这需要新的组织形式和工作流程来适应AI的介入[18]。
最后,AI4S基础设施建设是支撑其发展的关键,但也面临多重挑战[21,44]。这包括算力平台、数据平台、软件工具和开源社区等多个层面。当前,高性能计算资源的高需求限制了大型模型在科研领域的广泛应用[22]。同时,数据基础设施不完善、算力平台不足以及软件工具尚不成熟等问题依然存在[31]。构建高效、共享、安全的科研基础设施和技术生态,对于推动AI4S的深入发展至关重要[21,44]。未来的努力方向应包括推动基础设施的升级、建立标准化数据共享平台、开发更易用的软件工具,以及促进活跃的开源社区。
综上所述,人才培养、组织协同与基础设施建设是AI4S发展不可或缺的支撑要素,解决这些挑战需要系统性的政策支持、教育改革和资源投入。
7.4 伦理、法规与社会影响挑战
随着大模型在科学发现中的应用日益深入,伦理、法规与社会影响等方面的挑战也随之凸显。
在伦理层面,数据隐私与安全是 AI 驱动科研面临的核心问题 [22,23,37]。保障个人隐私和数据安全至关重要 [37],联邦学习和差分隐私等技术被视为解决数据隐私问题的潜在方案 [22]。算法偏见亦是一个重要议题,需避免产生歧视和不公平现象 [37],这与模型透明度挑战密切相关,尤其是在临床决策等关键应用中,模型决策过程的不透明性引发了伦理担忧 [22]。此外,AI 驱动科研通常需要大量计算资源和数据,这可能加剧不同科研机构间的不平等现象 [5]。在使用 AI 工具进行学术写作与研究时,保持道德和透明性至关重要,以确保学术研究的完整性和原创性不被损害 [41],同时也要防范对 AI 工具的过度依赖可能削弱研究人员的独立思考和创新能力 [41]。因此,在 AI 工具的实施和应用中,必须充分考虑伦理问题和模型透明度 [22]。
在社会影响方面,随着 AI 承担更多科研任务,科学家在研究过程中的角色可能需要重新定义 [5],这或许会引发关于职业未来的思考与调整 [5]。
法规与监管体系的完善是 AI 驱动科研顺利发展的重要保障。目前,各国的药品监管机构对于 AI 在药物研发中的应用尚未形成统一的监管标准和指南 [35],这种法规政策的不完善性对 AI 制药等领域的实际应用构成了阻碍。为确保 AI 驱动科研成果的安全可靠应用,特别是在生物医学等领域,模型必须通过严格的临床验证才能应用于实际医疗场景 [22]。同时,需要遵循相关的法律法规和伦理规范 [37],并制定明确的指南以确保大模型在医疗决策等领域得到负责任的使用,并进行持续评估以保持与最新知识同步 [22]。建立和完善适用于 AI 驱动科学发现的监管体系和政策框架,对于引导技术健康发展、防范潜在风险至关重要。
8. 未来发展趋势与展望
本章旨在综合已有研究洞见,对人工智能(AI)驱动的科学发现的未来发展趋势进行系统性展望。这一展望涵盖了多个关键维度,包括驱动科学发现的核心AI技术的演进方向、科学研究模式与生态体系的深刻变革,以及在特定科学领域可能实现的潜在突破。通过对这些维度的深入分析,本章旨在构建一个全面且具有前瞻性的视角,揭示AI在未来如何进一步重塑科学研究的格局。
8.1 技术发展方向
展望未来,大模型在科学发现领域的应用将持续演进,其核心技术发展方向涵盖多个维度。一个关键趋势是 AI 模型性能的持续提升,具体体现在向更通用、更智能、更可解释以及具备更强因果推理能力的方向发展[6,37,38,39]。为实现这一目标,研究需要聚焦于改进数据质量与多样性,这被视为提升模型性能的基础[22,31]。同时,模型复杂性与精细度的提高、更高效自动化的模型训练和优化方法[31],以及开发高效的微调方法以更好地适配特定科学任务,均是性能提升的重要途径[22]。技术架构的演进,例如尝试采用 Transformer 等更新的模型架构,有望进一步提升模型性能[1]。模型的效率和对复杂输入的依赖性降低也代表了重要的发展方向,如 HelixFold-Single 在蛋白质结构预测中通过无需多序列比对 (MSA) 输入实现的显著速度提升所示[28]。通用性和处理多样化输入的能力亦在提升,AlphaFold 3 通过加强对 Pair representation 的学习降低对 MSA 的依赖,使其模块更加通用,能处理更多不同类型的输入,并洞察细胞系统的复杂性,包括结构、相互作用和修饰[8,19]。大语言模型在改变实验设计流程方面展现出潜力,通过实现更高效、更灵活的工作流程,简化复杂问题并能通过反思和改进来增强实验计划[2]。特定领域的应用模型也展示出高性能,例如 BAI-Chem 2.0 在药物分子设计方面实现快速高效的生成,并在逆合成准确率上取得提升[18]。智能材料设计正成为可能,利用 AI 深度学习能力实现材料根据环境变化自调整、自修复、自适应和自组装等功能[29]。在模型可解释性和因果推理能力方面,提高生成过程的透明性,研究大模型内部机制以理解其生成科学假设的依据,是亟待解决的问题[6]。提升模型解释性有助于增强其在实际应用中的信任度和接受度[22]。
多模态数据的深度融合被视为提高模型性能和泛化能力的另一重要潜力方向[3,22,39,43,45]。通过整合文本、图像、基因序列等多种异构数据源,有望为科学研究提供更全面、更深入的洞察[22]。然而,目前许多研究尚未充分探讨多模态数据深度融合的具体技术发展[31]。
展望更远的未来,人工智能在科学发现中的发展方向包括自主发现系统和机器人科学家等概念的实现[7]。关键技术如人工智能代理模型、基础模型、逆向设计和数字孪生等将得到进一步发展和应用[7]。尽管部分文献尚未详细阐述这些具体的未来技术方向[22,31],但相关概念已开始涌现,例如智能化科学设施和跨学科 AI 科研助手的构想,旨在构建能够辅助甚至主导科研流程的系统[18]。此外,通过自然语言作为界面使 AI 工具更易于科学家使用,也有助于扩展 AI 在材料研究等领域的应用范围[9]。隐私保护技术如联邦学习和差分隐私等的发展,对于解决科学研究中敏感数据的应用问题至关重要[22]。模型融合技术,结合多种大模型的优势以应对复杂的科学任务,也是未来的一个发展方向[22]。
尽管现有研究在模型速度提升、特定任务性能优化及基础架构演进方面取得进展,但对于模型通用智能、深层可解释性、因果推理能力以及多模态数据的高效融合等更为广泛且关键的技术发展方向,仍需更深入的探索和突破[28,31]。未来研究应系统性地解决这些挑战,推动大模型从辅助工具向更智能、更自主的科学发现引擎转变。
8.2 科研模式与生态演进
大模型驱动的科学发现正在深刻影响未来的科研模式与生态体系,核心在于构建人机互补性的协作范式。在此模式下,人工智能将作为“虚拟专家”辅助科学家进行决策分析和科学探索[5,7,18,37,42]。大型语言模型(LLMs)通过自动化实验过程中重复且耗时的任务,显著提升研究效率,尤其是在处理大型数据集时[2]。通过预训练、微调和工具增强学习,基于LLM的智能体可以获得特定于任务的能力,进一步自动化科学研究中的实验工作流[2]。
应对复杂科学问题需要跨学科的深度融合,这是人工智能驱动科学发现的关键推动力之一[5,37]。跨学科合作的不断加强将推动模型应用于更多领域[31]。智能化科学设施的构想,以及打造跨学科的人工智能科研助手,体现了对应这种融合需求的响应[18]。
为了适应这一新范式,科研教育体系亟需进行革新,以培养具备复合型知识和技能的人才[5,42,44]。这要求教育更加注重跨领域知识的整合和人机协作能力的培养。
未来AI4S生态的发展,将伴随基础设施的进一步完善和政策支持的持续增强。国家层面的政策支持,如在《新一代人工智能发展规划》指导下的协调推进,将加速人才、技术、数据、算力等核心要素的汇聚,形成推动“人工智能驱动的科学研究”的政策合力[21]。在平台支撑方面,国家正在加快建设新一代人工智能公共算力开放创新平台[21],为人工智能驱动的科学研究提供基础算力保障。
科研模式也正朝着开放科学和平台化方向演进[42]。开源社区和平台,如DeepModeling,集成了机器学习与物理模型相结合的科学计算方法、模型和基础设施,并开发了具有强大迁移能力的预训练模型(如DPA)[10],极大地降低了新体系研究的数据需求[10]。HelixFold-Single的开源和在线服务提供,也体现了科研成果共享和快速应用的趋势,促进了开放的科研生态[28]。机制创新鼓励用户单位围绕业务需求参与模型研究与算法创新,并积极开放数据与资源[21],进一步促进了平台协同和资源共享。去中心化科学(DeSci)利用Web3工具(包括智能合约和区块链)旨在解决科学研究中的知识产权问题,促进科学数据的共享流通[18]。此外,公司可能会分拆内部开发的平台,以获取投资回报并避免潜在的竞争利益冲突[9],这也反映了平台模式在商业和研究领域的演变。尽管一些研究提到了跨学科合作的重要性,但对于人机协作模式、科研教育革新、基础设施与政策支持的具体细节、开放科学与平台科研的深入机制,以及去中心化组织等方面的探索仍需进一步深化[22,31]。
8.3 特定领域展望与潜在突破
人工智能(AI)和大型模型(LLMs)的兴起正在为自然科学的多个特定领域带来深刻变革,有望加速基础研究进展并推动实际应用突破。理解微观世界的基本原理并精确模拟微观粒子的状态,是药物、材料和化工等产业实现理性设计的关键,AI正是在此基础上发挥作用,从而引爆材料革命并重塑药物研发范式[9,16,26]。
在新材料发现与设计方面,AI与新材料技术的结合被视为双引擎,有望在多个领域带来革命性改变,显著加速新材料的研发进程[29]。这种结合不仅提高了效率,也为探索未知材料空间提供了强大的工具。
在药物研发领域,AI的潜力尤为突出。分子生物学的核心问题在于理解并最终调节生物系统中复杂的原子相互作用[4]。大型模型如AlphaFold 3在此方向上迈出了重要一步,证明了在一个统一框架中准确预测大范围生物分子系统结构的可能性,无需人为区分蛋白质结构预测和配体对接[4]。蛋白质结构预测速度的大幅提升,对于开发针对特定癌症、病毒感染的治疗方法,以及开发新型抗生素、靶向药和高效工业酶具有重要的推动作用[28]。值得注意的是,尽管基于蛋白质结构信息的重要性推演出的展望较为具体,但全面的药物研发突破需要整合更广泛的生物分子相互作用信息[28]。AlphaFold有望帮助科学家以前所未有的精准度设计靶向受体的分子,从而加速并提高药物设计的成功率[19]。AI制药特别在肿瘤、神经退行性疾病和罕见病等存在未被满足医疗需求的领域,有望开发出更有效的治疗药物,显示出巨大的市场潜力[35]。
基因治疗作为新兴的治疗手段,也正受益于AI的发展。例如,基于深度学习的工具DeepCas13为基础研究和临床提供了全新的预测能力,不仅可以用于研究一系列科学问题,更有望在未来直接通过靶向RNA的方式治疗人类疾病,特别是在基因治疗领域[1]。有观点认为,未来5至10年将是基因疗法的黄金时期,预示着AI在此领域的巨大应用前景[1]。
除了上述特定领域,AI和大型模型还在多个层面提升生物科学数据的价值并解决特定难题。LLMs除了具备自动执行实验的潜力,还能通过生成自然语言解释和构建有意义的可视化来协助数据分析[2]。AutoGen等通用框架允许通过多个可定制的智体(LLM)创建不同的应用程序,为复杂的科学任务提供了灵活的解决方案[2]。在更广泛的生物医学领域,LLMs在医疗资源匮乏地区通过轻量级模型提供基本诊断支持方面展现潜力,旨在实现更有效和公平的医疗服务[22]。尽管如此,当前一些研究在展望生物科学大模型的未来贡献时,尚未明确指出在新材料、药物研发(除已有讨论外)、基因治疗、精神/神经疾病临床前筛选等特定领域可能加速突破的潜力,以及AI在这些领域解决特定难题的详细展望,这提示了未来研究可以进一步细化和深入的方向[22,31]。AI在解决如精神/神经疾病临床前筛选等特定难题方面,是未来重要的研究方向,有望为这些复杂的疾病提供新的诊断和治疗策略[45]。
9. 结论
本综述系统梳理了大模型在科学发现领域应用的研究进展,揭示了其在多个基础学科及应用领域的强大潜力和革命性影响。研究表明,以大型语言模型和特定科学领域大模型为代表的人工智能技术,正以前所未有的速度和能力加速科学研究进程,提高研究效率,并拓展人类探索未知世界的边界[1,5,10,15,17,19]。
在大模型的赋能下,蛋白质结构预测领域取得了里程碑式的突破,AlphaFold系列模型能够准确预测蛋白质结构,AlphaFold 3甚至能在统一框架下预测多种生物分子的相互作用,极大地推动了生命科学的发展[4,8,30]。HelixFold-Single等模型将蛋白质结构预测速度提升数百倍,实现了秒级预测,打破了传统方法的速度瓶颈,预示着AI大模型在生物计算领域的广泛应用前景,尤其是在药物研发、疾病治疗和工业酶开发等方面[28]。此外,深度学习模型如DeepCas13为基因疗法提供了新的预测工具,有望加速基因编辑相关研究与临床应用[1]。生物科学大模型和大型语言模型(LLMs)凭借其强大的表达与泛化能力,在基因组学、医学影像诊断、临床试验等生物医学领域展现出巨大潜力,能够解读生物学复杂语言、优化工作流程、分析海量数据并生成新见解,从而提高医学研究的效率和准确性,推动精准医疗发展[3,22,23,31,32,36,37,38,43]。AI在药物研发全流程中的应用尤为突出,能显著降低研发成本、提高效率和成功率,加速新药研发进程[16,33,35,40]。在材料科学和工科领域,AI正深刻改变从材料设计、性能预测到实验自动化的各个环节,加速新材料的发现和应用,为可持续发展做出贡献[11,29,45]。更有研究探索利用AI,特别是结合文献和数据驱动的方法,加速科学假设的生成,显著提高了假设的质量和人类决策的准确性,为科研工作者提供了强有力的辅助工具,极大地减少了资源和时间成本[2,6,27]。总体而言,AI的角色已从早期的辅助手段转变为驱动科研范式变革的核心力量,推动科研向自动化、模型化和智能化方向演进[13,15,42]。
尽管大模型在科学发现中展现出巨大潜力,当前研究和应用仍面临诸多挑战。数据问题是核心挑战之一,包括数据隐私与安全、数据集质量和多样性不足,以及某些领域(如AlphaFold的应用)面临的数据短缺问题[6,19,22,23,25]。模型自身存在局限性,如模型可解释性不足、可靠性有待提高,以及预测复杂系统(如多域蛋白质、多个构象、动态过程)的能力尚需提升[3,6,8,22,23,34]。高计算资源需求也限制了模型的广泛部署[22]。此外,AI驱动的科研范式变革带来了人才、组织、伦理等多层面的挑战,需要解决伦理框架的构建和学术诚信等问题[25,37,41,42]。
面向未来,推动AI驱动的科学发现发展需要多方面的协同努力[12]。强化人机协作是关键方向,未来的科学突破将是人类智慧与AI能力深度融合的结晶[5,16]。大力推动跨学科融合,特别是促进传统学科专家与人工智能研究者的深度合作,是探索新的应用场景和提高AI技术针对性的重要途径[5,11,21,26,30,32,42,45]。构建完善的伦理框架和治理体系,确保AI在科学研究中的负责任使用,是保障其健康可持续发展的基础[25,37,41]。
加强基础设施建设,包括高水平计算平台、高质量科学数据库和智能化科学设施的构建,为AI for Science提供坚实支撑[7,18,42]。同时,应关注提高数据质量和多样性、增强模型可解释性、发展高效微调方法等技术层面的改进,并积极推动国际合作与多学科复合型人才培养[6,22,23,42]。
展望未来,AI for Science作为一种新兴的科研范式,将为解决人类面临的重大全球性难题,如气候变化、能源危机、重大疾病等,开辟新的可能性空间[5,10,15]。通过持续的技术创新、跨界合作和生态体系建设,大模型有望在更多基础和应用领域发挥关键作用,共同推动科学研究迈入一个更加智能、高效、开放的新纪元。
References
[1] DeepCas13:深度学习助力CRISPR-Cas13d基因疗法预测 https://baijiahao.baidu.com/s?id=1764520407526701569&wfr=spider&for=pc
[2] LLM4SR:大语言模型在科学研究中的应用、挑战与未来 https://blog.csdn.net/yorkhunter/article/details/145221407
[3] 大型语言模型在生物技术和药物研发中的应用 https://zhuanlan.zhihu.com/p/628451808
[4] Nature发布AlphaFold 3.0:AI生物分子预测迎来新突破 https://baijiahao.baidu.com/s?id=1798572927669442308&wfr=spider&for=pc
[5] AI驱动科研:突破、挑战与人机协作的新范式 https://baijiahao.baidu.com/s?id=1805553248869879735&wfr=spider&for=pc
[6] LLM与Bit-Flip方法:探索科学假设生成 https://juejin.cn/post/7498356464966680612
[7] 美国能源部领衔:人工智能驱动科学研究的新进展与部署动向 https://mp.weixin.qq.com/s?\_\_biz=MzAxMjY2OTkxOA==&mid=2652069420&idx=3&sn=9efd11e52b4db07e2281b398279883dc&chksm=813366579a0d70b3c1548b2940632db0ddb250541f310efd8ba9dc42b6169fc8388bb1a7aaf7&scene=27
[8] AlphaFold精准预测蛋白质结构的AI原理 https://baijiahao.baidu.com/s?id=1803338988602623571&wfr=spider&for=pc
[9] AI引爆材料革命:重塑研发与未来范式 https://mp.weixin.qq.com/s?\_\_biz=MzU5OTI0MjIyOQ==&mid=2247529626&idx=1&sn=b6116d10df0cf6fb28fc8706f9fbb53a&chksm=feb5d000c9c25916787e35d1b9f33cefc8b858ce523852a6a9aea370a0005b1b11fb4cf5fa37&scene=27
[10] AI for Science:赋能科研新范式,加速科技革命 https://baijiahao.baidu.com/s?id=1760429344437754892&wfr=spider&for=pc
[11] AI赋能材料科学:现状与未来展望 https://baijiahao.baidu.com/s?id=1823849128173995112&wfr=spider&for=pc
[12] 医疗大模型爆发与赋能:近300项院内外实践 https://baijiahao.baidu.com/s?id=1831521520874405125&wfr=spider&for=pc
[13] 人工智能驱动科研新范式及学科应用研究 https://mp.weixin.qq.com/s?\_\_biz=MzkwODMxMTE5Mw==&mid=2247510545&idx=1&sn=1360708f25a12056b79277b31133aa28&chksm=c152279fd6a7efcc791dda9f104bc675c073fdcb1f80f7adc06d131d78a83537f63417a7f4cc&scene=27
[14] ColabFold:让AlphaFold2蛋白质结构预测触手可及 https://zhuanlan.zhihu.com/p/6318560306
[15] 从AI4S到智能科学:科研新范式解读 http://cn.chinagate.cn/news/2023-05/11/content\_85267249.shtml
[16] 2025,AI重塑药物研发的三个方向 https://baijiahao.baidu.com/s?id=1821458066462198728&wfr=spider&for=pc
[17] AlphaFolding:以4D扩散模型预测蛋白质动态结构 https://baijiahao.baidu.com/s?id=1823664231488841829&wfr=spider&for=pc
[18] 上海交大 AI4S 团队提出智能化科学设施构想,打造跨学科 AI 科研助手 https://hub.baai.ac.cn/view/35143
[19] DeepMind AlphaFold:AI助力蛋白质结构预测,加速药物研发 https://baijiahao.baidu.com/s?id=1831365699897107586&wfr=spider&for=pc
[20] YEF2024论坛:AI驱动科学创新 https://zhuanlan.zhihu.com/p/694557979
[21] 科技部部署AI驱动科研,权威专家详解 https://baijiahao.baidu.com/s?id=1761532717860485965&wfr=spider&for=pc
[22] 大语言模型在生物医学中的应用、挑战与未来展望 https://blog.csdn.net/lvaolan168/article/details/143920516
[23] 基因组学深度学习:技术、应用与未来 https://baijiahao.baidu.com/s?id=1769826666902644700&wfr=spider&for=pc
[24] 中南大学DPFunc:基于深度学习的蛋白质功能预测新突破 https://baijiahao.baidu.com/s?id=1820763200138835859&wfr=spider&for=pc
[25] AI药物研发:全流程、挑战与未来趋势 https://baijiahao.baidu.com/s?id=1831113850419937604&wfr=spider&for=pc
[26] AI驱动科研专项启动,北京亮出“自然科学界ChatGPT”等成果 https://baijiahao.baidu.com/s?id=1761876662336058166&wfr=spider&for=pc
[27] 文献数据融合:AI助力科研假设生成提速 https://baijiahao.baidu.com/s?id=1824084784954523162&wfr=spider&for=pc
[28] 人工智能大模型:蛋白质结构预测速度再获突破,提速数百倍! http://baijiahao.baidu.com/s?id=1787979411795732022&wfr=spider&for=pc
[29] AI与新材料:科技革命双引擎 http://www.kepu.gov.cn/newspaper/2024-08/30/content\_221542.html
[30] AlphaFold:AI驱动蛋白质结构预测,助力生物医药革命 https://www.msbd123.com/85147.html
[31] 生物科学大模型:驱动生物医学研究的未来与挑战 https://blog.csdn.net/weixin\_41888295/article/details/136326924
[32] AI赋能生物医学:大模型应用盘点与未来展望 https://mp.weixin.qq.com/s?\_\_biz=Mzg3OTE3NjA4Nw==&mid=2247612233&idx=1&sn=d8257901bdad66a6f838c9461c8e0057&chksm=ceebb0d7dd03e8096ae64f59c13148ffaa4c47a3a4154769c84741cbdb9ca0bfc352c2280e9f&scene=27
[33] AI赋能药物研发:机遇、挑战与未来 https://mp.weixin.qq.com/s?\_\_biz=MjM5NTI3MDE0NQ==&mid=2653769433&idx=1&sn=ec59383357662cf4562929b186ccaa1d&chksm=bc62b8d0175a138131a360e5757272ee4554894e9e1ff48a2513f0ea87c28a594a8cd67f4202&scene=27
[34] 蛋白质结构预测:最新进展、挑战与未来展望 https://zhuanlan.zhihu.com/p/677830837
[35] AI制药:引领医药创新,重塑产业未来 https://baijiahao.baidu.com/s?id=1824190321579435373&wfr=spider&for=pc
[36] AI重塑生命科学:从药物研发到全领域深远影响 https://baijiahao.baidu.com/s?id=1792228734506821100&wfr=spider&for=pc
[37] 生物科学大模型:驱动生物医学研究的未来 https://my.oschina.net/u/4299156/blog/10983724
[38] 大模型:原理与生物医学未来应用 https://qianfanmarket.baidu.com/article/detail/1160988
[39] 多模态AI赋能生物医学研究:新纪元与创新应用 https://it.sohu.com/a/765478252\_121836467
[40] 人工智能赋能药物开发:现状、挑战与未来展望 https://zhuanlan.zhihu.com/p/26851429356
[41] AI工具:学术写作与研究的最佳实践 https://zhuanlan.zhihu.com/p/700057779
[42] 人工智能驱动的科研范式变革与特征 https://www.zgcsswdx.cn/info/10272.html
[43] 深度学习:精准医疗诊断前沿 https://blog.csdn.net/qq\_53139964/article/details/142577905
[44] 人工智能赋能科研创新:政策支持与发展挑战 https://baijiahao.baidu.com/s?id=1794548188709440082&wfr=spider&for=pc
[45] AI赋能工科科研:现状与未来 https://baijiahao.baidu.com/s?id=1823849367002385886&wfr=spider&for=pc